11 Point Pattern Analysis
Point pattern analysis is concerned with describing patterns of points over space and making inference about the process that could have generated an observed pattern. The main focus here lies on the information carried in the locations of the points, and typically these locations are not controlled by sampling but a result of a process we are interested in, such as animal sightings, accidents, disease cases, or tree locations. This is opposed to geostatistical processes (Chapter 12) where we have values of some phenomenon everywhere but observations limited to a set of locations that we can control, at least in principle. Hence, in geostatistical problems the prime interest is not in the observation locations but in estimating the value of the observed phenomenon at unobserved locations. Point pattern analysis typically assumes that for an observed area, all points are available, meaning that locations without a point are not unobserved as in a geostatistical process, but are observed and contain no point. In terms of random processes, in point processes locations are random variables, where, in geostatistical processes the measured variable is a random field with locations fixed.
This chapter is confined to describing the very basics of point pattern analysis, using package spatstat (Baddeley, Turner, and Rubak 2022), and related packages by the same authors. The spatstat book of Baddeley, Rubak, and Turner (2015) gives a comprehensive introduction to point pattern theory and the use of the spatstat package family, which we will not try to copy. Inclusion of particular topics in this chapter should not be seen as an expression that these are more relevant than others. In particular, this chapter tries to illustrate interfaces existing between spatstat and the more spatial data science oriented packages sf and stars. A further book that introduces point patterns analysis is Stoyan et al. (2017). R package stpp (Gabriel et al. 2022) for analysing spatiotemporal point processes is discussed in Gabriel, Rowlingson, and Diggle (2013).
Important concepts of point patterns analysis are the distinction between a point pattern and a point process: the latter is the stochastic process that, when sampled, generates a point pattern. A dataset is always a point pattern, and inference involves figuring out the properties of a process that could have generated a pattern like the one we observed. Properties of a spatial point process include
- first order properties: the intensity function measures the number of points per area unit; this function is spatially varying for a inhomogeneous point process
- second order properties: given a constant or varying intensity function, describe whether points are distributed independently from one another, tend to attract each other (clustering), or repulse each other (more regularly distributed than under complete spatial randomness)
11.1 Observation window
Point patterns have an observation window. Consider the points generated randomly by
# Libraries
import geopandas as gpd
import pandas as pd
import numpy as np
from shapely.geometry import Point, box
from shapely.ops import unary_union
import matplotlib.pyplot as plt
# Generate random points
n = 30
np.random.seed(13531) # Remove this line to create another random sequence
x = np.random.uniform(0, 1, n)
y = np.random.uniform(0, 1, n)
xy = gpd.GeoDataFrame({'geometry': [Point(xy) for xy in zip(x, y)]})then these points are (by construction) uniformly distributed, or completely spatially random, over the domain \([0,1] \times [0,1]\). For a larger domain, they are not uniform, for the two square windows w1 and w2 created by
this is shown in Figure 11.1.
Code
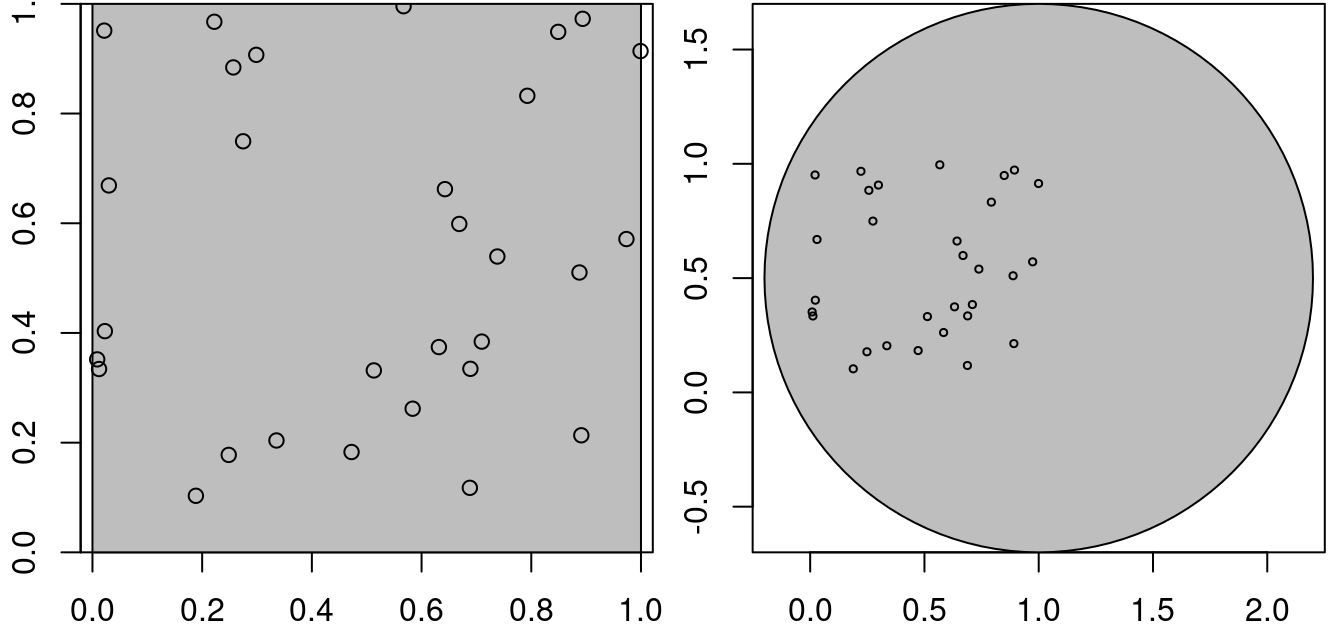
# Plot random points within observation windows
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
for ax, window, title in zip(axs, [w1, w2], ["Window 1", "Window 2"]):
ax.set_title(title)
ax.add_patch(plt.Rectangle((window.bounds[0], window.bounds[1]),
window.bounds[2] - window.bounds[0],
window.bounds[3] - window.bounds[1],
alpha=0.3, color='gray'))
ax.scatter(x, y)
plt.show()
Point patterns in spatstat are objects of class ppp that contain points and an observation window (an object of class owin). We can create a ppp from points by
library(spatstat) |> suppressPackageStartupMessages()
as.ppp(xy)
# Planar point pattern: 30 points
# window: rectangle = [0.009, 0.999] x [0.103, 0.996] unitsimport geopandas as gpd
from shapely.geometry import Point, Polygon
# Using previously created random points (xy)
# Define observation window (bounding box)
bbox = Polygon([(0, 0), (1, 0), (1, 1), (0, 1)])
# Create a GeoDataFrame as a point pattern
### EP: the following does not make sense IMO:
# xy['window'] = bbox
# print(xy.head())where we see that the bounding box of the points is used as observation window when no window is specified. If we add a polygonal geometry as the first feature of the dataset, then this is used as observation window:
(pp1 <- c(w1, st_geometry(xy)) |> as.ppp())
# Planar point pattern: 30 points
# window: polygonal boundary
# enclosing rectangle: [0, 1] x [0, 1] units
c1 <- st_buffer(st_centroid(w2), 1.2)
(pp2 <- c(c1, st_geometry(xy)) |> as.ppp())
# Planar point pattern: 30 points
# window: polygonal boundary
# enclosing rectangle: [-0.2, 2.2] x [-0.7, 1.7] unitsTo test for homogeneity, one could carry out a quadrat count, using an appropriate quadrat layout (a 3 \(\times\) 3 layout is shown in Figure 11.2)
par(mfrow = c(1, 2), mar = rep(0, 4))
q1 <- quadratcount(pp1, nx=3, ny=3)
q2 <- quadratcount(pp2, nx=3, ny=3)
plot(q1, main = "")
plot(xy, add = TRUE)
plot(q2, main = "")
plot(xy, add = TRUE)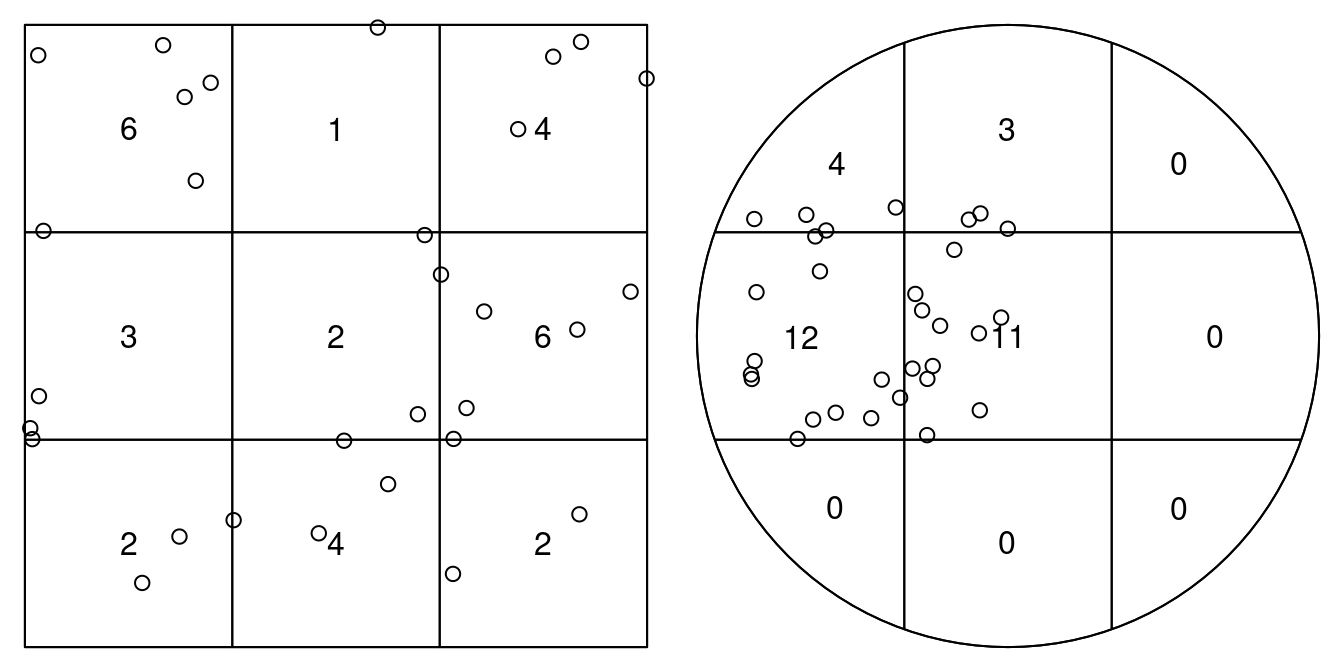
and carry out a \(\chi^2\) test on these counts:
quadrat.test(pp1, nx=3, ny=3)
# Warning: Some expected counts are small; chi^2 approximation may be
# inaccurate
#
# Chi-squared test of CSR using quadrat counts
#
# data: pp1
# X2 = 8, df = 8, p-value = 0.9
# alternative hypothesis: two.sided
#
# Quadrats: 9 tiles (irregular windows)
quadrat.test(pp2, nx=3, ny=3)
# Warning: Some expected counts are small; chi^2 approximation may be
# inaccurate
#
# Chi-squared test of CSR using quadrat counts
#
# data: pp2
# X2 = 43, df = 8, p-value = 2e-06
# alternative hypothesis: two.sided
#
# Quadrats: 9 tiles (irregular windows)which indicates that for the second case we have an indication that this is not a CSR (completely spatially random) pattern. As indicated by the warning, we should take the p-values with a large grain of salt because we have too small expected counts.
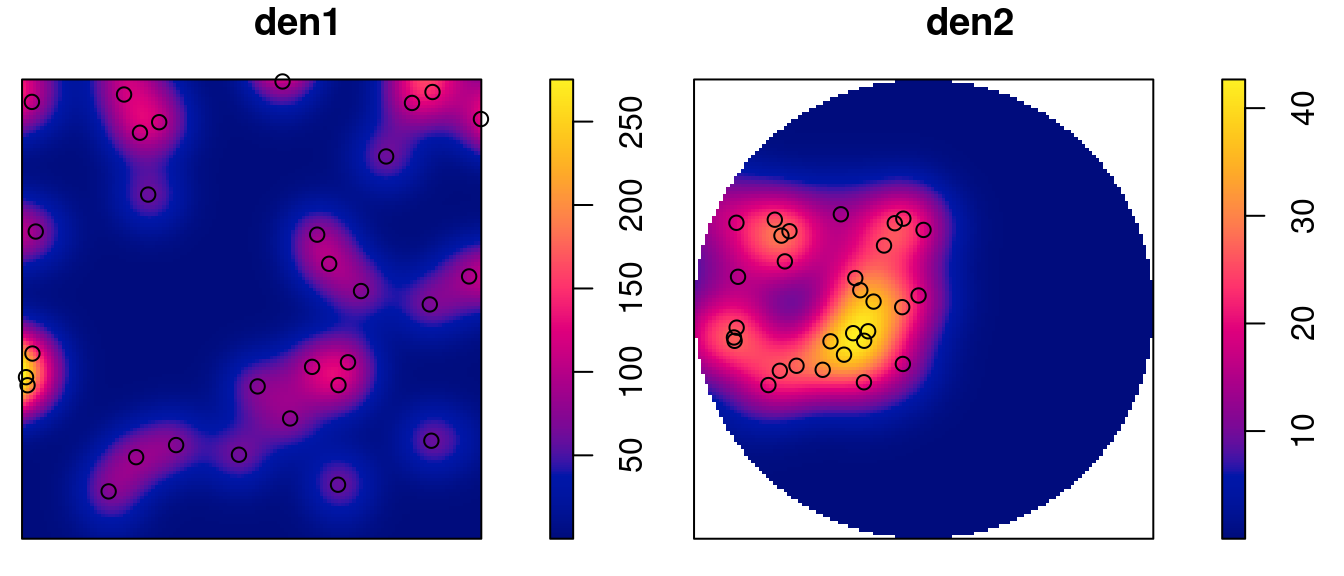
Kernel densities can be computed using density, where kernel shape and bandwidth can be controlled. Here, cross-validation is used by function bw.diggle to specify the bandwidth parameter sigma; plots are shown in Figure 11.3.
from scipy.stats import gaussian_kde
xy_coords = np.vstack((x, y))
kde = gaussian_kde(xy_coords)
# Create a grid to evaluate the KDE
x_grid = np.linspace(min(x) - 1, max(x) + 1, 100)
y_grid = np.linspace(min(y) - 1, max(y) + 1, 100)
X, Y = np.meshgrid(x_grid, y_grid)
positions = np.vstack([X.ravel(), Y.ravel()])
Z = kde(positions).reshape(X.shape)
# Plot the KDE
plt.figure(figsize=(8, 6))
plt.imshow(Z, origin='lower', aspect='auto', extent=(x_grid.min(), x_grid.max(), y_grid.min(), y_grid.max()), cmap='Blues')
plt.scatter(x, y, c='red', s=15, label="Data points")
plt.colorbar(label="Density")
# <matplotlib.colorbar.Colorbar object at 0x76ce532352e0>
plt.xlabel("X")
plt.ylabel("Y")
plt.title("2D Kernel Density Estimation (KDE)")
plt.legend()
plt.show()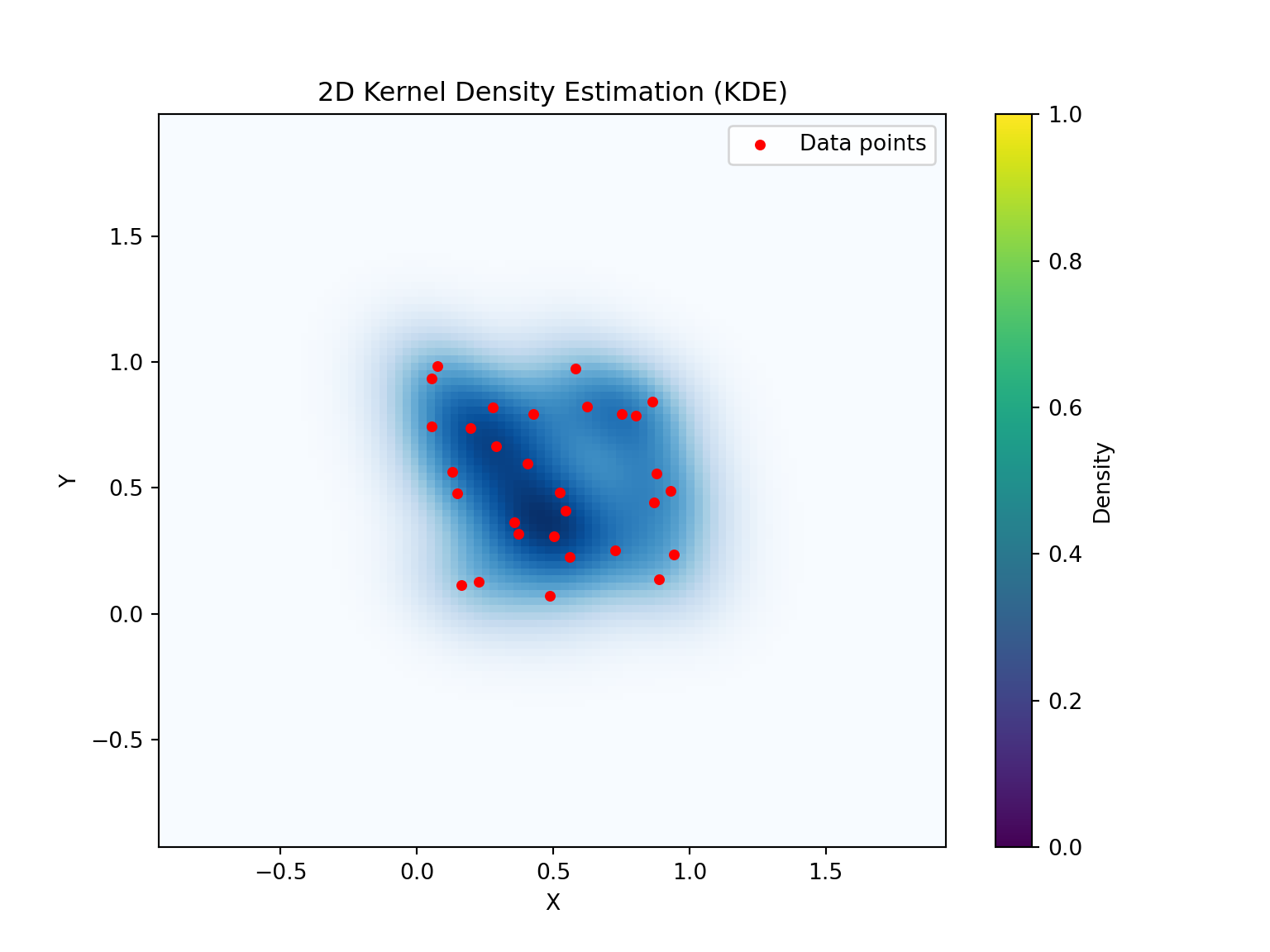
The density maps created this way are obviously raster images, and we can convert them into stars object by
library(stars)
# Loading required package: abind
s1 <- st_as_stars(den1)
(s2 <- st_as_stars(den2))
# stars object with 2 dimensions and 1 attribute
# attribute(s):
# Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
# v 6.28e-15 0.000153 0.304 6.77 13.1 42.7 3492
# dimension(s):
# from to offset delta x/y
# x 1 128 -0.2 0.0187 [x]
# y 1 128 -0.7 0.0188 [y]and we can verify that the area under the density surface is similar to the sample size (30), by
s1$a <- st_area(s1) |> suppressMessages()
s2$a <- st_area(s2) |> suppressMessages()
with(s1, sum(v * a, na.rm = TRUE))
# [1] 29
with(s2, sum(v * a, na.rm = TRUE))
# [1] 30.7import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
# Generate some random 2D data points
np.random.seed(42)
#x = np.random.normal(loc=0, scale=1, size=100)
#y = np.random.normal(loc=0, scale=1, size=100)
# Create a 2D KDE
xy = np.vstack([x, y])
kde = gaussian_kde(xy)
# Create a grid to evaluate the KDE
x_grid = np.linspace(min(x) - 1, max(x) + 1, 100)
y_grid = np.linspace(min(y) - 1, max(y) + 1, 100)
X, Y = np.meshgrid(x_grid, y_grid)
positions = np.vstack([X.ravel(), Y.ravel()])
Z = kde(positions).reshape(X.shape)
# Calculate the pixel area
x_grid_size = x_grid[1] - x_grid[0]
y_grid_size = y_grid[1] - y_grid[0]
pixel_area = x_grid_size * y_grid_size
# Calculate the total area under the KDE surface
total_area = (Z * pixel_area).sum()
print(f"Total area under the KDE surface: {total_area}")
# Total area under the KDE surface: 0.9999999999470728
More exciting applications involve modelling the density surface as a function of external variables. Suppose we want to model the density of pp2 as a Poisson point process (meaning that points do not interact with each other), where the intensity is a function of distance to the centre of the “cluster”, and these distance are available in a stars object:
pt <- st_sfc(st_point(c(0.5, 0.5)))
st_as_sf(s2, as_points = TRUE, na.rm = FALSE) |>
st_distance(pt) -> s2$distwe can then model the densities using ppm, where the name of the point pattern object is used on the left-hand side of the formula:
(m <- ppm(pp2 ~ dist, data = list(dist = as.im(s2["dist"]))))
# Nonstationary Poisson process
# Fitted to point pattern dataset 'pp2'
#
# Log intensity: ~dist
#
# Fitted trend coefficients:
# (Intercept) dist
# 4.54 -4.25
#
# Estimate S.E. CI95.lo CI95.hi Ztest Zval
# (Intercept) 4.54 0.341 3.87 5.21 *** 13.32
# dist -4.25 0.701 -5.62 -2.88 *** -6.06The returned object is of class ppm, and can be plotted: Figure 11.4 shows the predicted surface. The prediction standard error can also be plotted.
Code
plot(m, se = FALSE)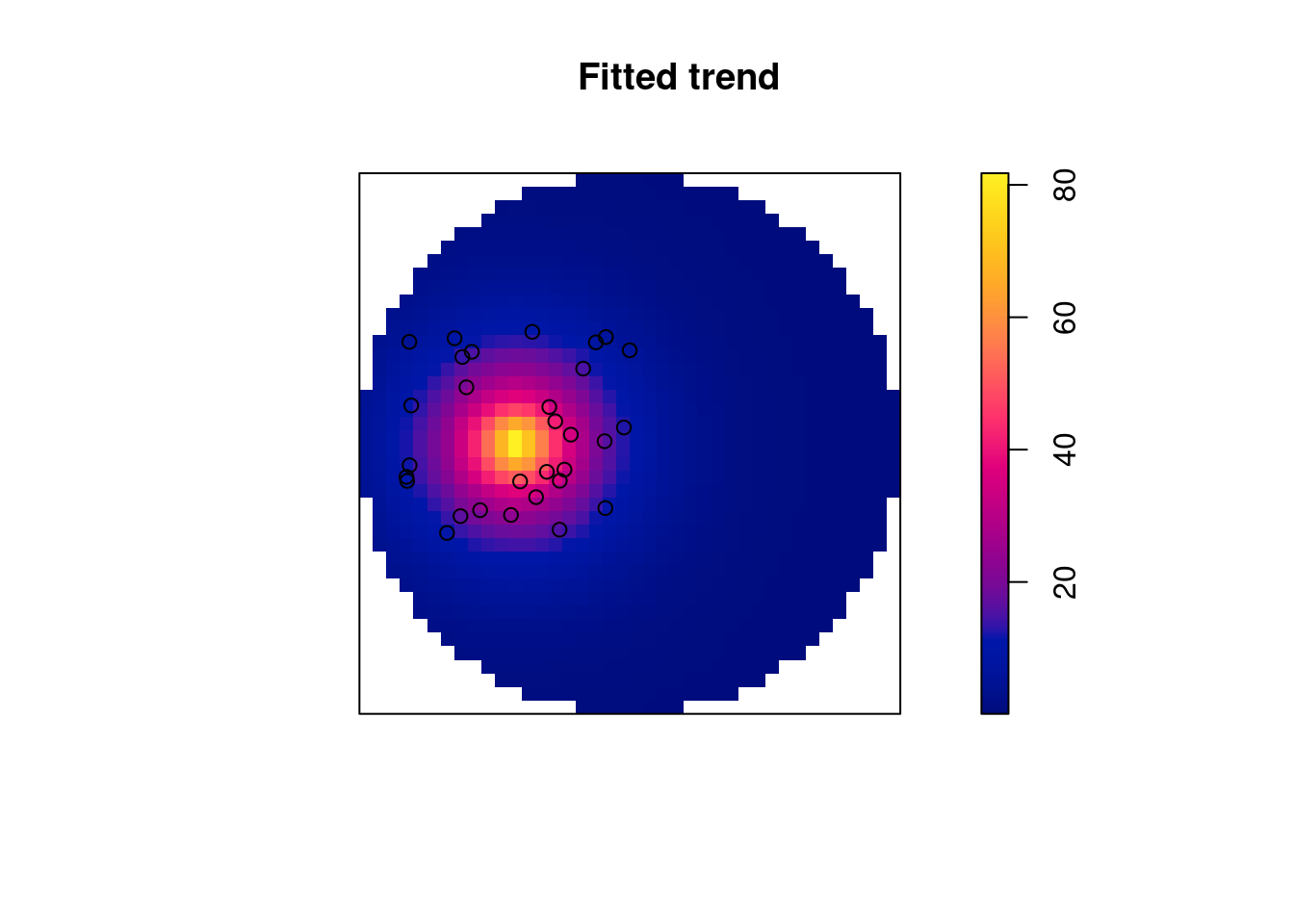
The model also has a predict method, which returns an im object that can be converted into a stars object by
predict(m, covariates = list(dist = as.im(s2["dist"]))) |>
st_as_stars()
# stars object with 2 dimensions and 1 attribute
# attribute(s):
# Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
# v 0.0694 0.527 2.12 6.62 7.3 89.9 3492
# dimension(s):
# from to offset delta x/y
# x 1 128 -0.2 0.0187 [x]
# y 1 128 -0.7 0.0187 [y]11.2 Coordinate reference systems
All routines in spatstat are layed out for two-dimensional data with Cartesian coordinates. If we try to convert an object with ellipsoidal coordinates, we get an error:
system.file("gpkg/nc.gpkg", package = "sf") |>
read_sf() |>
st_geometry() |>
st_centroid() |>
as.ppp()
# Error: Only projected coordinates may be converted to spatstat
# class objectsWhen converting to a spatstat data structure we lose the coordinate reference system we started with. It can be set back to sf or stars objects by using st_set_crs.
11.3 Marked point patterns, points on linear networks
A few more data types can be converted to and from spatstat. Marked point patterns are point patterns that have a “mark”, which is either a categorical label or a numeric label for each point. A dataset available in spatstat with marks is the longleaf pines dataset, containing diameter at breast height as a numeric mark:
longleaf
# Marked planar point pattern: 584 points
# marks are numeric, of storage type 'double'
# window: rectangle = [0, 200] x [0, 200] metres
ll <- st_as_sf(longleaf)
print(ll, n = 3)
# Simple feature collection with 585 features and 2 fields
# Geometry type: GEOMETRY
# Dimension: XY
# Bounding box: xmin: 0 ymin: 0 xmax: 200 ymax: 200
# CRS: NA
# First 3 features:
# spatstat.geom..marks.x. label geom
# NA NA window POLYGON ((0 0, 200 0, 200 2...
# 1 32.9 point POINT (200 8.8)
# 2 53.5 point POINT (199 10)Values can be converted back to ppp with
as.ppp(ll)
# Marked planar point pattern: 584 points
# Mark variables: spatstat.geom..marks.x., label
# window: polygonal boundary
# enclosing rectangle: [0, 200] x [0, 200] units Line segments, in spatstat objects of class psp can be converted back and forth to simple feature with LINESTRING geometries following a POLYGON feature with the observation window, as in
print(st_as_sf(copper$SouthLines), n = 5)
# Simple feature collection with 91 features and 1 field
# Geometry type: GEOMETRY
# Dimension: XY
# Bounding box: xmin: -0.335 ymin: 0.19 xmax: 35 ymax: 158
# CRS: NA
# First 5 features:
# label geom
# 1 window POLYGON ((-0.335 0.19, 35 0...
# 2 segment LINESTRING (3.36 0.19, 10.4...
# 3 segment LINESTRING (12.5 0.263, 11....
# 4 segment LINESTRING (11.2 0.197, -0....
# 5 segment LINESTRING (6.35 12.8, 16.5...Finally, point patterns on linear networks, in spatstat represented by lpp objects, can be converted to sf by
print(st_as_sf(chicago), n = 5)
# Simple feature collection with 620 features and 4 fields
# Geometry type: GEOMETRY
# Dimension: XY
# Bounding box: xmin: 0.389 ymin: 153 xmax: 1280 ymax: 1280
# CRS: NA
# First 5 features:
# label seg tp marks geom
# 1 window NA NA <NA> POLYGON ((0.389 153, 1282 1...
# 2 segment NA NA <NA> LINESTRING (0.389 1254, 110...
# 3 segment NA NA <NA> LINESTRING (110 1252, 111 1...
# 4 segment NA NA <NA> LINESTRING (110 1252, 198 1...
# 5 segment NA NA <NA> LINESTRING (198 1277, 198 1...where we only see the first five features; the points are also in this object, as variable label indicates
Potential information about network structure, how LINESTRING geometries are connected, is not present in the sf object. Package sfnetworks (van der Meer et al. 2022) would be a candidate package to hold such information in R or to pass on network data imported from OpenStreetMaps to spatstat.
11.4 Spatial sampling and simulating a point process
Package sf contains an st_sample method that samples points from MULTIPOINT, linear or polygonal geometries, using different spatial sampling strategies. It natively supports strategies “random”, “hexagonal”, “Fibonacci” (Section 11.5), and “regular”, where “regular” refers to sampling on a square regular grid and “hexagonal” essentially gives a triangular grid. For type “random”, it can return exactly the number of requested points, for other types this is approximate.
st_sample also interfaces point process simulation functions of spatstat, when other values for sampling type are chosen. For instance the spatstat function rThomas is invoked when setting type = Thomas (Figure 11.5):
The help function obtained by ?rThomas details the meaning of the parameters kappa, mu, and scale. Simulating point processes means that the intensity is given, not the sample size. The sample size within the observation window obtained this way is a random variable.
11.5 Simulating points on the sphere
Another spatial random sampling type supported by sf natively (in st_sample) is simulation of random points on the sphere. An example of this is shown in Figure 11.6, where points were constrained to those in oceans. Points approximately regularly distributed over a sphere are obtained by st_sample with type = "Fibonacci" (González 2010).
Code
par(mar = rep(0, 4), mfrow = c(1, 2))
library(s2)
g <- as_s2_geography(TRUE) # Earth
co <- s2_data_countries()
oc <- s2_difference(g, s2_union_agg(co)) # oceans
b <- s2_buffer_cells(as_s2_geography("POINT(-30 -10)"), 9800000) # visible half
i <- s2_intersection(b, oc) # visible ocean
co <- s2_intersection(b, co)
ortho = st_crs("+proj=ortho +lat_0=-10 +lon_0=-30")
# background:
st_transform(st_as_sfc(i), ortho) |> plot(col = 'lightblue')
st_transform(st_as_sfc(co), ortho) |> plot(col = NA, add = TRUE, border = 'grey')
# sampling randomly from globe:
sf_use_s2(FALSE) |> suppressMessages()
if (packageVersion("sf") >= "1.0.16") {
globe = st_as_stars() |> st_bbox() # st_sample only needs bbox
} else {
globe = st_as_stars() |> st_bbox() |> st_as_sfc()
}
pts <- st_sample(globe, 1000, exact = FALSE) |> suppressMessages()
sf_use_s2(TRUE) |> suppressMessages()
s2_intersection(pts, i) |> st_as_sfc() -> pts
# add:
st_transform(pts, ortho) |> plot(add = TRUE, pch = 3, cex = .5)
# right: background:
st_transform(st_as_sfc(i), ortho) |> plot(col = 'lightblue')
st_transform(st_as_sfc(co), ortho) |> plot(col = NA, add = TRUE, border = 'grey')
# Fibonacci:
sf_use_s2(FALSE) |> suppressMessages()
st_sample(globe, 1000, type = "Fibonacci", exact = FALSE) |> suppressMessages() -> pts
sf_use_s2(TRUE) |> suppressMessages()
pts |> s2_intersection(i) |> st_as_sfc() -> pts
st_transform(pts, ortho) |> plot(add = TRUE, pch = 3, cex = .5)
11.6 Exercises
- After loading spatstat, recreate the plot obtained by
plot(longleaf)by using ggplot2 andgeom_sf(), and bysf::plot(). - Convert the sample locations of the NO\(_2\) data used in Chapter 12 to a
pppobject, with a proper window. - Compute and plot the density of the NO\(_2\) dataset, import the density as a
starsobject, and compute the volume under the surface.