library(spdep) |> suppressPackageStartupMessages()
library(parallel)
glance_htest <- function(ht) c(ht$estimate,
"Std deviate" = unname(ht$statistic),
"p.value" = unname(ht$p.value))
set.seed(1)
(pol_pres15 |>
nrow() |>
rnorm() -> x) |>
moran.test(lw_q_B, randomisation = FALSE,
alternative = "two.sided") |>
glance_htest()
# Moran I statistic Expectation Variance
# -0.004772 -0.000401 0.000140
# Std deviate p.value
# -0.369320 0.71188915 Measures of Spatial Autocorrelation
When analysing areal data, it has long been recognised that, if present, spatial autocorrelation changes how we may infer, relative to the default assumption of independent observations. In the presence of spatial autocorrelation, we can predict the values of observation \(i\) from the values observed at \(j \in N_i\), the set of its proximate neighbours. Early results (Moran 1948; Geary 1954) entered into research practice gradually, for example the social sciences (Duncan, Cuzzort, and Duncan 1961). These results were then collated and extended to yield a set of basic tools of analysis (Cliff and Ord 1973, 1981).
Cliff and Ord (1973) generalised and extended the expression of the spatial weights matrix representation as part of the framework for establishing the distribution theory for join-count, Moran’s \(I\) and Geary’s \(C\) statistics. This development of what have become known as global measures, returning a single value of autocorrelation for the total study area, has been supplemented by local measures returning values for each areal unit (Getis and Ord 1992; Anselin 1995).
The measures offered by the spdep package have been written partly to provide implementations, but also to permit the comparative investigation of these measures and their implementation. For this reason, the implementations are written in R rather than compiled code, and they are generally slower but more flexible than implementations in the newly released rgeoda package (Li and Anselin 2021; Anselin, Li, and Koschinsky 2021).
15.1 Measures and process misspecification
It is not and has never been the case that Tobler’s first law of geography, “Everything is related to everything else, but near things are more related than distant things”, always holds absolutely. This is and has always been an oversimplification, disguising possible underlying entitation, support, and other misspecification problems. Are the units of observation appropriate for the scale of the underlying spatial process? Could the spatial patterning of the variable of interest for the chosen entitation be accounted for by another variable?
Tobler (1970) was published in the same special issue of Economic Geography as Olsson (1970), but Olsson does grasp the important point that spatial autocorrelation is not inherent in spatial phenomena, but often, is engendered by inappropriate entitation, by omitted variables and/or inappropriate functional form. The key quote from Olsson is on p. 228:
The existence of such autocorrelations makes it tempting to agree with Tobler (1970, 236 [the original refers to the pagination of a conference paper]) that ‘everything is related to everything else, but near things are more related than distant things.’ On the other hand, the fact that the autocorrelations seem to hide systematic specification errors suggests that the elevation of this statement to the status of ‘the first law of geography’ is at best premature. At worst, the statement may represent the spatial variant of the post hoc fallacy, which would mean that coincidence has been mistaken for a causal relation.
The status of the “first law” is very similar to the belief that John Snow induced from a map the cause of cholera as water-borne. It may be a good way of selling GIS, but it is inaccurate: Snow had a strong working hypothesis prior to visiting Soho, and the map was prepared after the Broad Street pump was disabled as documentation that his hypothesis held (Brody et al. 2000).
Measures of spatial autocorrelation unfortunately pick up other misspecifications in the way that we model data (Schabenberger and Gotway 2005; McMillen 2003). For reference, Moran’s \(I\) is given as (Cliff and Ord 1981, 17):
\[
I = \frac{n \sum_{(2)} w_{ij} z_i z_j}{S_0 \sum_{i=1}^{n} z_i^2}
\] where \(x_i, i=1, \ldots, n\) are \(n\) observations on the numeric variable of interest, \(z_i = x_i - \bar{x}\), \(\bar{x} = \sum_{i=1}^{n} x_i / n\), \(\sum_{(2)} = \stackrel{\sum_{i=1}^{n} \sum_{j=1}^{n}}{i \neq j}\), \(w_{ij}\) are the spatial weights, and \(S_0 = \sum_{(2)} w_{ij}\). First we test a random variable using the Moran test, here under the normality assumption (argument randomisation=FALSE, default TRUE). Inference is made on the statistic \(Z(I) = \frac{I - E(I)}{\sqrt{\mathrm{Var}(I)}}\), the z-value compared with the Normal distribution for \(E(I)\) and \(\mathrm{Var}(I)\) for the chosen assumptions; this x does not show spatial autocorrelation with these spatial weights:
The test however detects quite strong positive spatial autocorrelation when we insert a gentle trend into the data, but omit to include it in the mean model, thus creating a missing variable problem but finding spatial autocorrelation instead:
beta <- 0.0015
coords |>
st_coordinates() |>
subset(select = 1, drop = TRUE) |>
(function(x) x/1000)() -> t
(x + beta * t -> x_t) |>
moran.test(lw_q_B, randomisation = FALSE,
alternative = "two.sided") |>
glance_htest()
# Moran I statistic Expectation Variance
# 0.043403 -0.000401 0.000140
# Std deviate p.value
# 3.701491 0.000214If we test the residuals of a linear model including the trend, the apparent spatial autocorrelation disappears:
lm(x_t ~ t) |>
lm.morantest(lw_q_B, alternative = "two.sided") |>
glance_htest()
# Observed Moran I Expectation Variance Std deviate
# -0.004777 -0.000789 0.000140 -0.337306
# p.value
# 0.735886A comparison of implementations of measures of spatial autocorrelation shows that a wide range of measures is available in R in a number of packages, chiefly in the spdep package (Bivand 2022b), and that differences from other implementations can be attributed to design decisions (Bivand and Wong 2018). The spdep package also includes the only implementations of exact and saddlepoint approximations to global and local Moran’s I for regression residuals (Tiefelsdorf 2002; Bivand, Müller, and Reder 2009).
15.2 Global measures
Global measures consider the average level of spatial autocorrelation across all observations; they can of course be biased (as most spatial statistics) by edge effects where important spatial process components fall outside the study area.
Join-count tests for categorical data
We will begin by examining join-count statistics, where joincount.test takes a "factor" vector of values fx and a listw object, and returns a list of htest (hypothesis test) objects defined in the stats package, one htest object for each level of the fx argument. The observed counts are of neighbours with the same factor levels, known as same-colour joins.
args(joincount.test)# function (fx, listw, zero.policy = attr(listw, "zero.policy"),
# alternative = "greater", sampling = "nonfree", spChk = NULL,
# adjust.n = TRUE)The function takes an alternative argument for hypothesis testing, a sampling argument showing the basis for the construction of the variance of the measure, where the default "nonfree" choice corresponds to analytical permutation; the spChk argument is retained for backward compatibility. For reference, the counts of factor levels for the type of municipality or Warsaw borough are:
(pol_pres15 |>
st_drop_geometry() |>
subset(select = types, drop = TRUE) -> Types) |>
table()
#
# Rural Urban Urban/rural Warsaw Borough
# 1563 303 611 18Since there are four levels, we rearrange the list of htest objects to give a matrix of estimated results. The observed same-colour join-counts are tabulated with their expectations based on the counts of levels of the input factor, so that few joins would be expected between for example Warsaw boroughs, because there are very few of them. The variance calculation uses the underlying constants of the chosen listw object and the counts of levels of the input factor. The z-value is obtained in the usual way by dividing the difference between the observed and expected join-counts by the square root of the variance.
The join-count test was subsequently adapted for multi-colour join-counts (Upton and Fingleton 1985). The implementation as joincount.multi in spdep returns a table based on non-free sampling, and does not report p-values.
Types |> joincount.multi(listw = lw_q_B)
# Joincount Expected Variance z-value
# Rural:Rural 3087.000 2793.920 1126.534 8.73
# Urban:Urban 110.000 104.719 93.299 0.55
# Urban/rural:Urban/rural 656.000 426.526 331.759 12.60
# Warsaw Borough:Warsaw Borough 41.000 0.350 0.347 68.96
# Urban:Rural 668.000 1083.941 708.209 -15.63
# Urban/rural:Rural 2359.000 2185.769 1267.131 4.87
# Urban/rural:Urban 171.000 423.729 352.190 -13.47
# Warsaw Borough:Rural 12.000 64.393 46.460 -7.69
# Warsaw Borough:Urban 9.000 12.483 11.758 -1.02
# Warsaw Borough:Urban/rural 8.000 25.172 22.354 -3.63
# Jtot 3227.000 3795.486 1496.398 -14.70So far, we have used binary weights, so the sum of join-counts multiplied by the weight on that join remains integer. If we change to row standardised weights, where the weights are almost always fractions of 1, the counts, expectations and variances change, but there are few major changes in the z-values.
Using an inverse distance based listw object does, however, change the z-values markedly, because closer centroids are up-weighted relatively strongly:
Types |> joincount.multi(listw = lw_d183_idw_B)
# Joincount Expected Variance z-value
# Rural:Rural 3.46e+02 3.61e+02 4.93e+01 -2.10
# Urban:Urban 2.90e+01 1.35e+01 2.23e+00 10.39
# Urban/rural:Urban/rural 4.65e+01 5.51e+01 9.61e+00 -2.79
# Warsaw Borough:Warsaw Borough 1.68e+01 4.53e-02 6.61e-03 206.38
# Urban:Rural 2.02e+02 1.40e+02 2.36e+01 12.73
# Urban/rural:Rural 2.25e+02 2.83e+02 3.59e+01 -9.59
# Urban/rural:Urban 3.65e+01 5.48e+01 8.86e+00 -6.14
# Warsaw Borough:Rural 5.65e+00 8.33e+00 1.73e+00 -2.04
# Warsaw Borough:Urban 9.18e+00 1.61e+00 2.54e-01 15.01
# Warsaw Borough:Urban/rural 3.27e+00 3.25e+00 5.52e-01 0.02
# Jtot 4.82e+02 4.91e+02 4.16e+01 -1.38Moran’s \(I\)
The implementation of Moran’s \(I\) in spdep in the moran.test function has similar arguments to those of joincount.test, but sampling is replaced by randomisation to indicate the underlying analytical approach used for calculating the variance of the measure. It is also possible to use ranks rather than numerical values (Cliff and Ord 1981, 46). The drop.EI2 argument may be used to reproduce results where the final component of the variance term is omitted as found in some legacy software implementations.
args(moran.test)# function (x, listw, randomisation = TRUE, zero.policy =
# attr(listw, "zero.policy"), alternative = "greater", rank =
# FALSE, na.action = na.fail, spChk = NULL, adjust.n = TRUE,
# drop.EI2 = FALSE)The default for the randomisation argument is TRUE, but here we will simply show that the test under normality is the same as a test of least squares residuals with only the intercept used in the mean model. The analysed variable is first-round turnout proportion of registered voters in municipalities and Warsaw boroughs in the 2015 Polish presidential election. The spelling of randomisation is that of Cliff and Ord (1973).
pol_pres15 |>
st_drop_geometry() |>
subset(select = I_turnout, drop = TRUE) -> I_turnoutI_turnout |> moran.test(listw = lw_q_B, randomisation = FALSE) |>
glance_htest()
# Moran I statistic Expectation Variance
# 0.691434 -0.000401 0.000140
# Std deviate p.value
# 58.461349 0.000000The lm.morantest function also takes a resfun argument to set the function used to extract the residuals used for testing, and clearly lets us model other salient features of the response variable (Cliff and Ord 1981, 203). To compare with the standard test, we are only using the intercept here and, as can be seen, the results are the same.
lm(I_turnout ~ 1, pol_pres15) |>
lm.morantest(listw = lw_q_B) |>
glance_htest()
# Observed Moran I Expectation Variance Std deviate
# 0.691434 -0.000401 0.000140 58.461349
# p.value
# 0.000000The only difference between tests under normality and randomisation is that an extra term is added if the kurtosis of the variable of interest indicates a flatter or more peaked distribution, where the measure used is the classical measure of kurtosis. Under the default randomisation assumption of analytical randomisation, the results are largely unchanged.
(I_turnout |>
moran.test(listw = lw_q_B) -> mtr) |>
glance_htest()
# Moran I statistic Expectation Variance
# 0.691434 -0.000401 0.000140
# Std deviate p.value
# 58.459835 0.000000 From the very beginning in the early 1970s, interest was shown in Monte Carlo tests, also known as Hope-type tests and as permutation bootstrap. By default, moran.mc returns a "htest" object, but may simply use boot::boot internally and return a "boot" object when return_boot=TRUE. In addition the number of simulations needs to be given as nsim; that is the number of times the values of the observations are shuffled at random.
The bootstrap permutation retains the outcomes of each of the random permutations, reporting the observed value of the statistic, here Moran’s \(I\), the difference between this value and the mean of the simulations under randomisation (equivalent to \(E(I)\)), and the standard deviation of the simulations under randomisation.
If we compare the Monte Carlo and analytical variances of \(I\) under randomisation, we typically see few differences, arguably rendering Monte Carlo testing unnecessary.
Geary’s global \(C\) is implemented in geary.test largely following the same argument structure as moran.test. The Getis-Ord \(G\) test includes extra arguments to accommodate differences between implementations, as Bivand and Wong (2018) found multiple divergences from the original definitions, often to omit no-neighbour observations generated when using distance band neighbours. It is given by Getis and Ord (1992), on page 194. For \(G^*\), the \(i \neq j\) summation constraint is relaxed by including \(i\) as a neighbour of itself (thereby also removing the no-neighbour problem, because all observations have at least one neighbour).
Finally, the empirical Bayes Moran’s \(I\) takes account of the denominator in assessing spatial autocorrelation in rates data (Assunção and Reis 1999). Until now, we have considered the proportion of valid votes cast in relation to the numbers entitled to vote by spatial entity, but using EBImoran.mc we can try to accommodate uncertainty in extreme rates in entities with small numbers entitled to vote. There is, however, little impact on the outcome in this case.
Global measures of spatial autocorrelation using spatial weights objects based on graphs of neighbours are, as we have seen, rather blunt tools, which for interpretation depend critically on a reasoned mean model of the variable in question. If the mean model is just the intercept, the global measures will respond to all kinds of misspecification, not only spatial autocorrelation. The choice of entities for aggregation of data will typically be a key source of misspecification.
15.3 Local measures
Building on insights from the weaknesses of global measures, local indicators of spatial association began to appear in the first half of the 1990s (Anselin 1995; Getis and Ord 1992, 1996).
In addition, the Moran plot was introduced, plotting the values of the variable of interest against their spatially lagged values, typically using row-standardised weights to make the axes more directly comparable (Anselin 1996). The moran.plot function also returns an influence measures object used to label observations exerting more than proportional influence on the slope of the line representing global Moran’s \(I\). In Figure 15.1, we can see that there are many spatial entities exerting such influence. These pairs of observed and lagged observed values make up in aggregate the global measure, but can also be explored in detail. The quadrants of the Moran plot also show low-low pairs in the lower left quadrant, high-high in the upper right quadrant, and fewer low-high and high-low pairs in the upper left and lower right quadrants. In moran.plot, the quadrants are split on the means of the variable and its spatial lag; alternative splits are on zero for the centred variable and the spatial lag of the centred variable.
Code
I_turnout |>
moran.plot(listw = lw_q_W, labels = pol_pres15$TERYT,
cex = 1, pch = ".", xlab = "I round turnout",
ylab = "lagged turnout") -> infl_W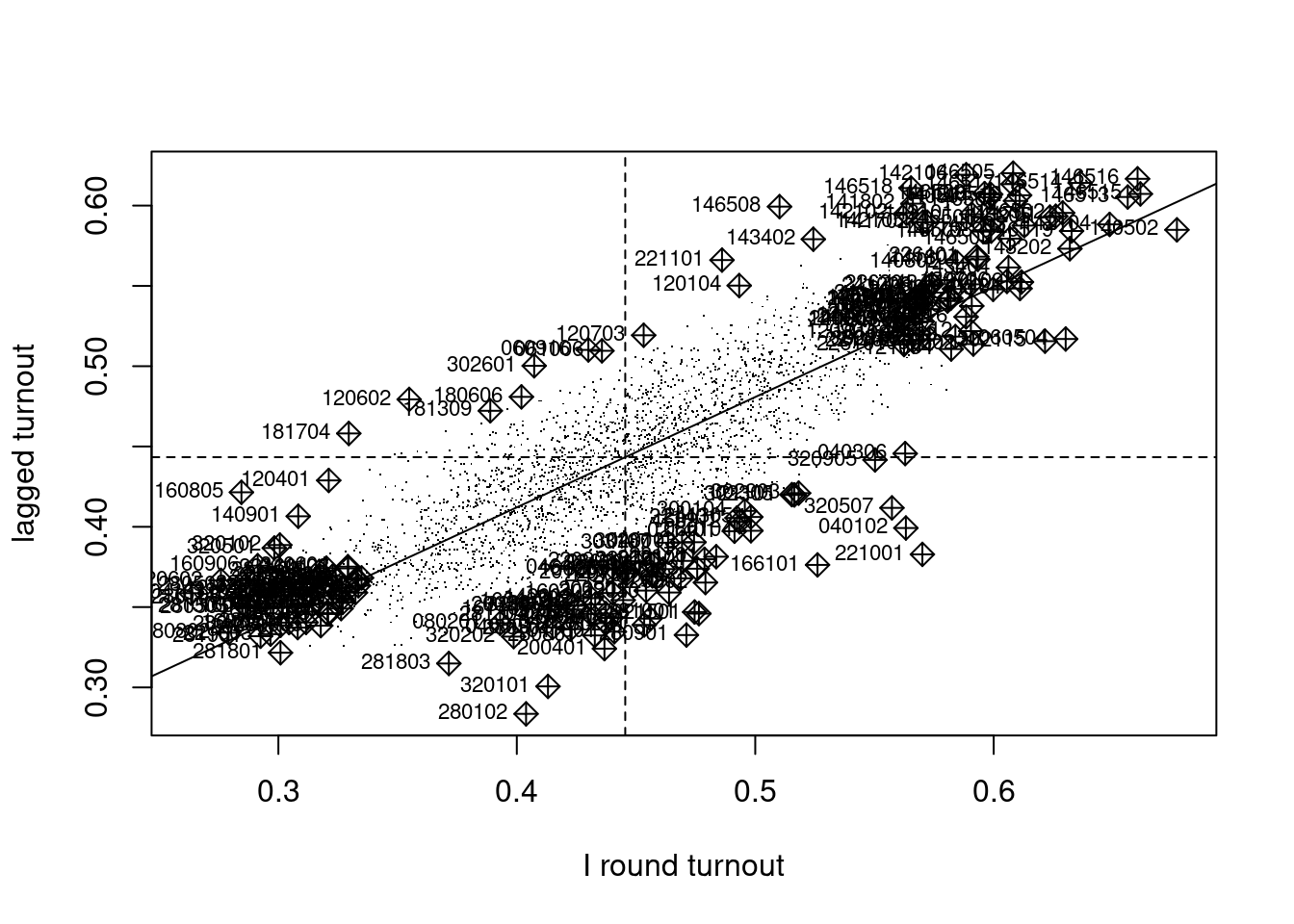
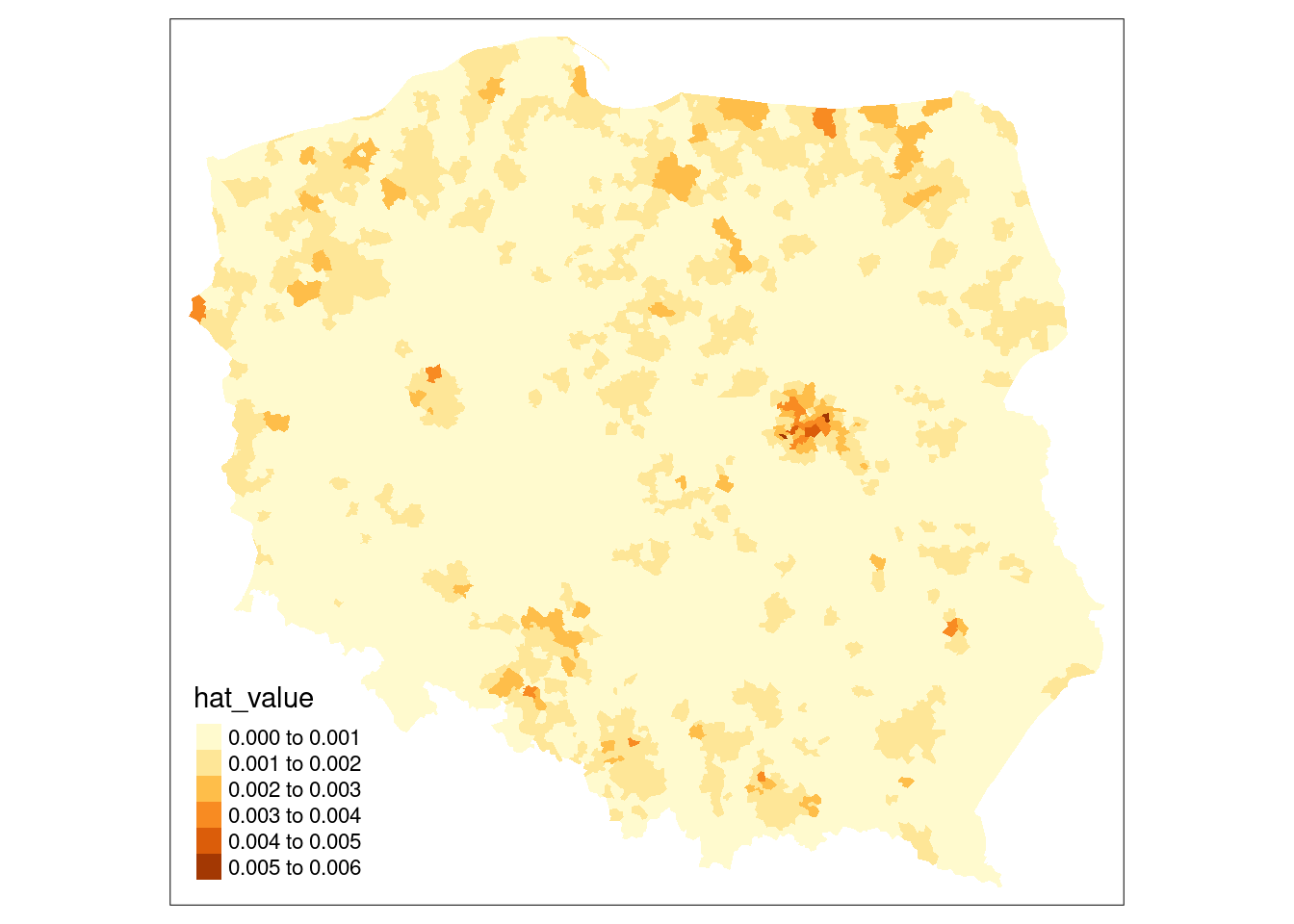
If we extract the hat value influence measure from the returned object, Figure 15.2 suggests that some edge entities exert more than proportional influence (perhaps because of row standardisation), as do entities in or near larger urban areas.
pol_pres15$hat_value <- infl_W$hat
if (tmap4) {
tm_shape(pol_pres15) +
tm_fill("hat_value", fill.scale = tm_scale(values = "brewer.yl_or_br"),
fill.legend = tm_legend(item.r = 0, frame = FALSE,
position = tm_pos_in("left", "bottom"))
)
} else {
tm_shape(pol_pres15) + tm_fill("hat_value")
}
Local Moran’s \(I_i\)
Bivand and Wong (2018) discuss issues impacting the use of local indicators, such as local Moran’s \(I_i\) and local Getis-Ord \(G_i\). Some issues affect the calculation of the local indicators, others inference from their values. Because \(n\) statistics may be calculated from the same number of observations, there are multiple comparison problems that need to be addressed. Caldas de Castro and Singer (2006) conclude, based on a typical dataset and a simulation exercise, that the false discovery rate (FDR) adjustment of probability values will certainly give a better picture of interesting clusters than no adjustment. Following this up, Anselin (2019) explores the combination of FDR adjustments with the use of redefined “significance” cutoffs (Benjamin et al. 2018), for example \(0.01\), \(0.005\), and \(0.001\) instead of \(0.1\), \(0.05\), and \(0.01\); the use of the term interesting rather than significant is also preferred. This is discussed further in Bivand (2022a). As in the global case, misspecification remains a source of confusion, and, further, interpreting local spatial autocorrelation in the presence of global spatial autocorrelation is challenging (Ord and Getis 2001; Tiefelsdorf 2002; Bivand, Müller, and Reder 2009).
args(localmoran)# function (x, listw, zero.policy = attr(listw, "zero.policy"),
# na.action = na.fail, conditional = TRUE, alternative =
# "two.sided", mlvar = TRUE, spChk = NULL, adjust.x = FALSE)In an important clarification, Sauer et al. (2021) show that the comparison of standard deviates for local Moran’s \(I_i\) based on analytical formulae and conditional permutation in Bivand and Wong (2018) was based on a misunderstanding. Sokal, Oden, and Thomson (1998) provide alternative analytical formulae for standard deviates of local Moran’s \(I_i\) based either on total or conditional permutation, but the analytical formulae used in Bivand and Wong (2018), based on earlier practice, only use total permutation, and consequently do not match the simulation conditional permutations. Thanks to a timely pull request, localmoran now has a conditional argument (default TRUE) using alternative formulae from the appendix of Sokal, Oden, and Thomson (1998). The mlvar and adjust.x arguments to localmoran are discussed in Bivand and Wong (2018), and permit matching with other implementations. Taking "two.sided" probability values (the default), we obtain:
I_turnout |>
localmoran(listw = lw_q_W) -> locmThe \(I_i\) local indicators when summed and divided by the sum of the spatial weights equal global Moran’s \(I\), showing the possible presence of positive and negative local spatial autocorrelation:
all.equal(sum(locm[,1])/Szero(lw_q_W),
unname(moran.test(I_turnout, lw_q_W)$estimate[1]))
# [1] TRUEUsing stats::p.adjust to adjust for multiple comparisons, we see that over 15% of the 2495 local measures have p-values < 0.005 if no adjustment is applied, but only 1.5% using Bonferroni adjustment to control the family-wise error rate, with two other choices shown: "fdr" is the Benjamini and Hochberg (1995) false discovery rate (almost 6%) and "BY" (Benjamini and Yekutieli 2001), another false discovery rate adjustment (about 2.5%):
pva <- function(pv) cbind("none" = pv,
"FDR" = p.adjust(pv, "fdr"), "BY" = p.adjust(pv, "BY"),
"Bonferroni" = p.adjust(pv, "bonferroni"))
locm |>
subset(select = "Pr(z != E(Ii))", drop = TRUE) |>
pva() -> pvsp
f <- function(x) sum(x < 0.005)
apply(pvsp, 2, f)
# none FDR BY Bonferroni
# 385 149 64 38In the global measure case, bootstrap permutations may be used as an alternative to analytical methods for possible inference, where both the theoretical development of the analytical variance of the measure, and the permutation scheme, shuffle all of the observed values. In the local case, conditional permutation should be used, fixing the value at observation \(i\) and randomly sampling from the remaining \(n-1\) values to find randomised values at neighbours. Conditional permutation is provided as function localmoran_perm, which may use multiple compute nodes to sample in parallel if provided, and permits the setting of a seed for the random number generator across the compute nodes. The number of simulations nsim also controls the precision of the ranked estimates of the probability value based on the rank of observed \(I_i\) among the simulated values:
library(parallel)
invisible(spdep::set.coresOption(max(detectCores()-1L, 1L)))
I_turnout |>
localmoran_perm(listw = lw_q_W, nsim = 9999,
iseed = 1) -> locm_pThe outcome is that over 15% of observations have two sided p-values < 0.005 without multiple comparison adjustment, and about 1.5% with Bonferroni adjustment, when the p-values are calculated using the standard deviate of the permutation samples and the normal distribution.
Since the variable under analysis may not be normally distributed, the p-values can also be calculated by finding the rank of the observed \(I_i\) among the rank-based simulated values, and looking up the probability value from the uniform distribution taking the alternative choice into account:
Now the "BY" and Bonferroni counts of interesting locations are zero with 9999 samples, but may be recovered by increasing the sample count to 999999 if required; the FDR adjustment and interesting cutoff 0.005 yields about 5% locations.
Code
if (tmap4) {
pv_brks <- c(0, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.2, 0.5, 0.75, 1)
tm_shape(pol_pres15) +
tm_polygons(fill=c("locm_pv", "locm_std_pv", "locm_p_pv"),
fill.legend = tm_legend("Pseudo p-values\nLocal Moran's I",
frame=FALSE, item.r = 0),
fill.scale = tm_scale(breaks = pv_brks, values="-brewer.yl_or_br"),
fill.free=FALSE, lwd=0.01) +
tm_facets_wrap(columns=2, rows=2) +
tm_layout(panel.labels = c("Analytical conditional",
"Permutation std. dev.", "Permutation rank"))
} else {
tm_shape(pol_pres15) +
tm_fill(c("locm_pv", "locm_std_pv", "locm_p_pv"),
breaks=pv_brks,
title = "Pseudo p-values\nLocal Moran's I",
palette="-YlOrBr") +
tm_facets(free.scales = FALSE, ncol = 2) +
tm_layout(panel.labels = c("Analytical conditional",
"Permutation std. dev.",
"Permutation rank"))
}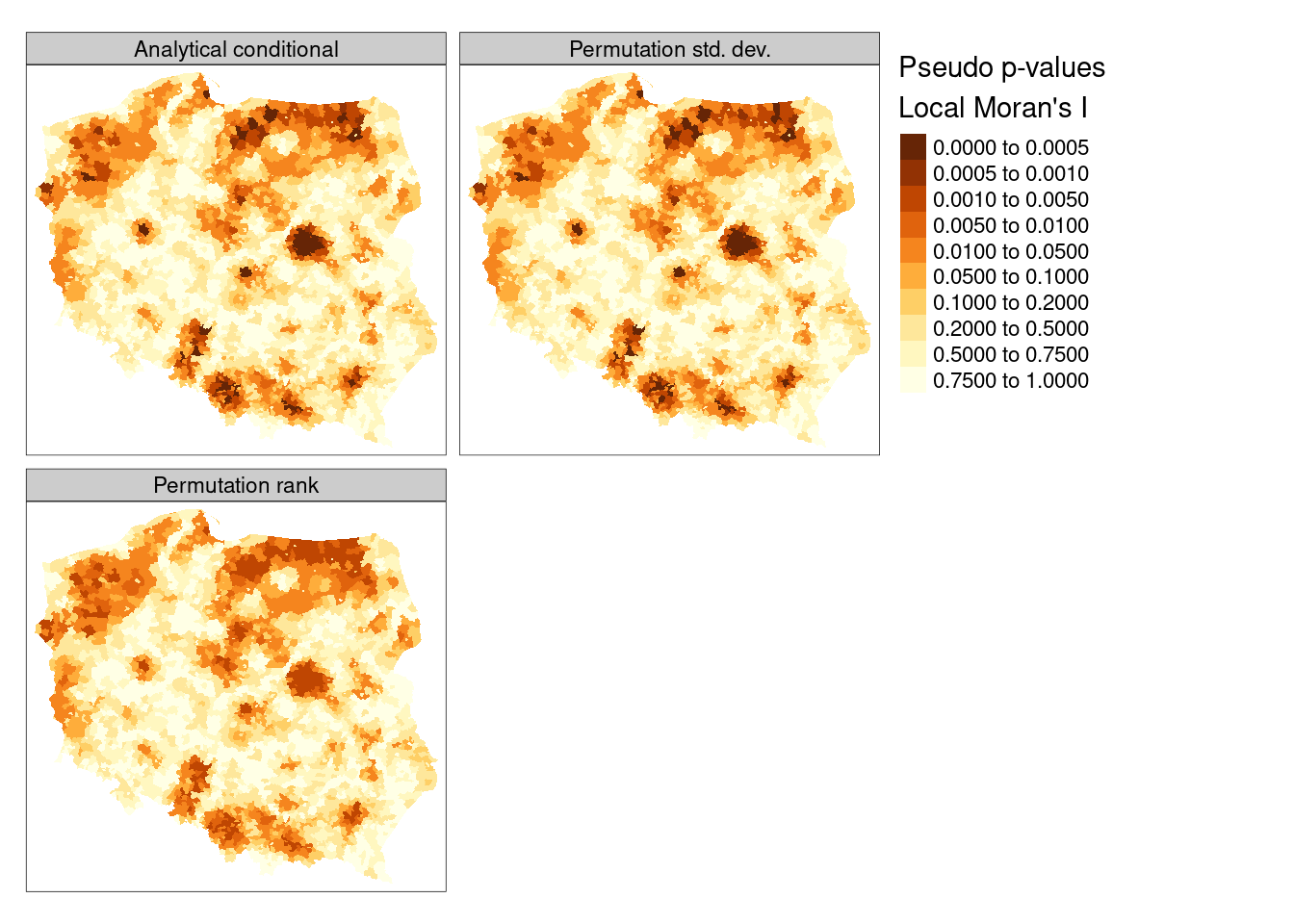
Proceeding using the FDR adjustment and an interesting location cutoff of \(0.005\), we can see from Figure 15.3 that the adjusted probability values for the analytical conditional approach, the approach using the moments of the sampled values from permutation sampling, and the approach using the ranks of observed values among permutation samples all yield similar maps, as the distribution of the input variable is quite close to normal.
In presenting local Moran’s \(I\), use is often made of “hotspot” maps. Because \(I_i\) takes high values both for strong positive autocorrelation of low and high values of the input variable, it is hard to show where “clusters” of similar neighbours with low or high values of the input variable occur. The quadrants of the Moran plot are used, by creating a categorical quadrant variable interacting the input variable and its spatial lag split at their means. The quadrant categories are then set to NA if, for the chosen probability value and adjustment, \(I_i\) would not be considered interesting. Here, for the FDR adjusted conditional analytical probability values (Figure 15.3, upper left panel), 53 observations belong to "Low-Low" cluster cores, and 96 to "High-High" cluster cores, similarly for the standard deviate-based permutation p-values (Figure 15.3, upper right panel), but the rank-based permutation p-values reduce the "High-High" count and increase the "Low-Low" count Figure 15.3 lower left panel:
quadr <- attr(locm, "quadr")$mean
a <- table(addNA(quadr))
locm |> hotspot(Prname="Pr(z != E(Ii))", cutoff = 0.005,
droplevels=FALSE) -> pol_pres15$hs_an_q
locm_p |> hotspot(Prname="Pr(z != E(Ii))", cutoff = 0.005,
droplevels=FALSE) -> pol_pres15$hs_ac_q
locm_p |> hotspot(Prname="Pr(z != E(Ii)) Sim", cutoff = 0.005,
droplevels = FALSE) -> pol_pres15$hs_cp_q
b <- table(addNA(pol_pres15$hs_an_q))
c <- table(addNA(pol_pres15$hs_ac_q))
d <- table(addNA(pol_pres15$hs_cp_q))
t(rbind("Moran plot quadrants" = a, "Analytical cond." = b,
"Permutation std. cond." = c, "Permutation rank cond." = d))
# Moran plot quadrants Analytical cond.
# Low-Low 1040 53
# High-Low 264 0
# Low-High 213 0
# High-High 978 96
# <NA> 0 2346
# Permutation std. cond. Permutation rank cond.
# Low-Low 53 56
# High-Low 0 0
# Low-High 0 0
# High-High 95 71
# <NA> 2347 2368pol_pres15$hs_an_q <- droplevels(pol_pres15$hs_an_q)
pol_pres15$hs_ac_q <- droplevels(pol_pres15$hs_ac_q)
pol_pres15$hs_cp_q <- droplevels(pol_pres15$hs_cp_q)Code
if (tmap4) {
pal <- rev(RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)])
tm_shape(pol_pres15) +
tm_polygons(fill = c("hs_an_q", "hs_ac_q", "hs_cp_q"),
fill.legend = tm_legend("Turnout hotspot status \nLocal Moran's I",
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01, fill.free = FALSE) +
tm_facets_wrap(columns = 2, rows = 2) +
tm_layout(panel.labels = c("Analytical conditional",
"Permutation std. cond.", "Permutation rank cond."))
} else {
tm_shape(pol_pres15) +
tm_fill(c("hs_an_q", "hs_ac_q", "hs_cp_q"),
colorNA = "grey95", textNA="Not \"interesting\"",
title = "Turnout hotspot status \nLocal Moran's I",
palette = RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)]) +
tm_facets(free.scales = FALSE, ncol = 2) +
tm_layout(panel.labels = c("Analytical conditional",
"Permutation std. cond.",
"Permutation rank cond."))
}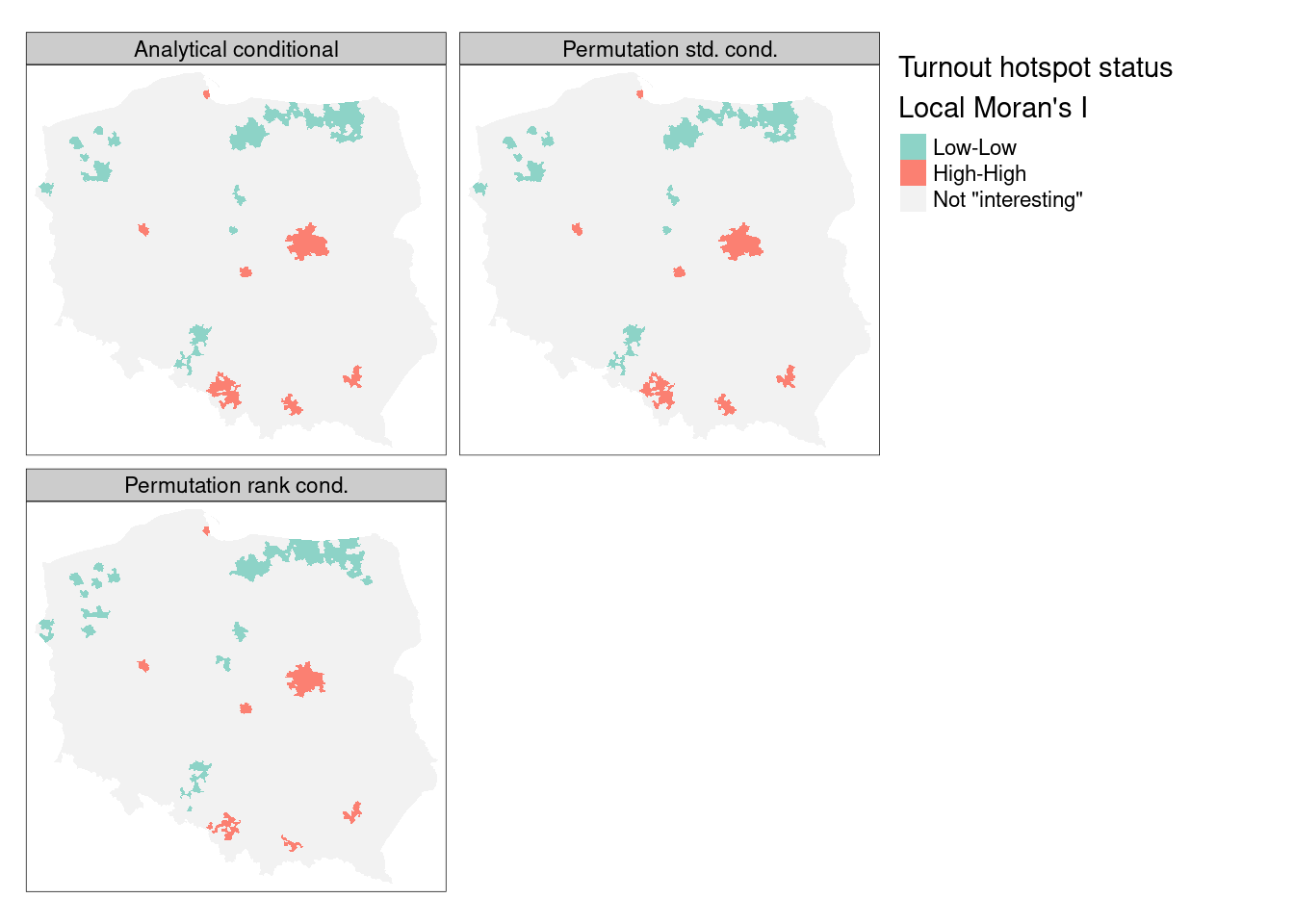
Figure 15.4 shows that there is very little difference between the FDR-adjusted interesting clusters with a choice of an \(\alpha=0.005\) probability value cutoff for the three approaches of analytical conditional standard deviates, permutation-based standard deviates, and rank-based probability values; the "High-High" cluster cores are metropolitan areas.
Tiefelsdorf (2002) argues that standard approaches to the calculation of the standard deviates of local Moran’s \(I_i\) should be supplemented by numerical estimates, and shows that saddlepoint approximations are a computationally efficient way of achieving this goal. The localmoran.sad function takes a fitted linear model as its first argument, so we first fit a null (intercept only) model, but use case weights because the numbers entitled to vote vary greatly between observations:
lm(I_turnout ~ 1) -> lm_nullSaddlepoint approximation is as computationally intensive as conditional permutation, because, rather than computing a simple measure on many samples, a good deal of numerical calculation is needed for each local approximation:
lm_null |> localmoran.sad(nb = nb_q, style = "W",
alternative = "two.sided") |>
summary() -> locm_sad_nullThe chief advantage of the saddlepoint approximation is that it takes a fitted linear model rather than simply a numerical variable, so the residuals are analysed. With an intercept-only model, the results are similar to local Moran’s \(I_i\), but we can weight the observations, here by the count of those entitled to vote, which should down-weight small units of observation:
lm(I_turnout ~ 1, weights = pol_pres15$I_entitled_to_vote) ->
lm_null_weights
lm_null_weights |>
localmoran.sad(nb = nb_q, style = "W",
alternative = "two.sided") |>
summary() -> locm_sad_null_weightsNext we add the categorical variable distinguishing between rural, urban and other types of observational unit:
lm(I_turnout ~ Types, weights=pol_pres15$I_entitled_to_vote) ->
lm_types
lm_types |> localmoran.sad(nb = nb_q, style = "W",
alternative = "two.sided") |>
summary() -> locm_sad_typesCode
if (tmap4) {
pal <- RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)]
tm_shape(pol_pres15) +
tm_polygons(fill = c("hs_cp_q", "locm_sad0", "locm_sad1", "locm_sad2"),
fill.legend = tm_legend("Turnout hotspot status \nLocal Moran's I",
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01, fill.free = FALSE) +
tm_facets_wrap(columns = 2, rows = 2) +
tm_layout(panel.labels = c("Permutation rank",
"saddlepoint null", "saddlepoint weighted null",
"saddlepoint weighted types"))
} else {
tm_shape(pol_pres15) +
tm_fill(c("hs_cp_q", "locm_sad0", "locm_sad1", "locm_sad2"),
colorNA = "grey95", textNA = "Not \"interesting\"",
title = "Turnout hotspot status \nLocal Moran's I",
palette =RColorBrewer::brewer.pal(4, "Set3")[c(1, 4, 2)]) +
tm_facets(free.scales = FALSE, ncol = 2) +
tm_layout(panel.labels = c("Permutation rank",
"saddlepoint null", "saddlepoint weighted null",
"saddlepoint weighted types"))
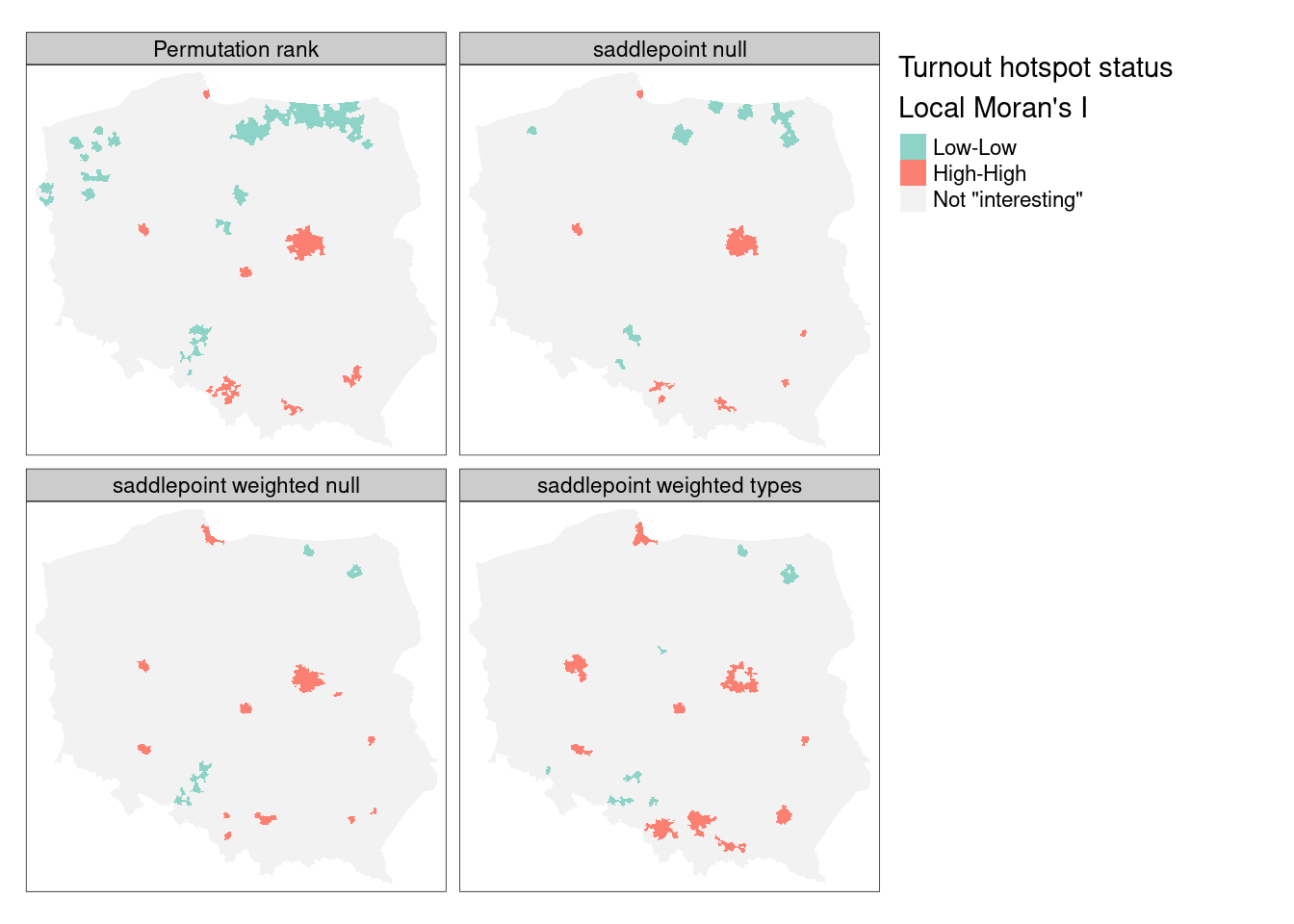
}
rbind(null = append(table(addNA(pol_pres15$locm_sad0)),
c("Low-High" = 0), 1),
weighted = append(table(addNA(pol_pres15$locm_sad1)),
c("Low-High" = 0), 1),
type_weighted = append(table(addNA(pol_pres15$locm_sad2)),
c("Low-High" = 0), 1))
# Low-Low Low-High High-High <NA>
# null 19 0 55 2421
# weighted 9 0 52 2434
# type_weighted 13 0 81 2401Figure 15.5 includes the permutation rank cluster cores for comparison (upper left panel). Because saddlepoint approximation permits richer mean models to be used, and possibly because the approximation approach is inherently local, relating regression residual values at \(i\) to those of its neighbours, the remaining three panels diverge somewhat. The intercept-only (null) model is fairly similar to standard local Moran’s \(I_i\), but weighting by counts of eligible voters removes most of the "Low-Low" cluster cores. Adding the type categorical variable strengthens the urban "High-High" cluster cores but removes the Warsaw boroughs as interesting cluster cores. The central boroughs are surrounded by other boroughs, all with high turnout, not driven by autocorrelation but by being metropolitan boroughs. It is also possible to use saddlepoint approximation where the global spatial process has been incorporated, removing the conflation of global and local spatial autocorrelation in standard approaches.
The same can also be accomplished using exact methods, but may require more tuning as numerical integration may fail, returning NaN rather than the exact estimate of the standard deviate (Bivand, Müller, and Reder 2009):
lm_types |> localmoran.exact(nb = nb_q, style = "W",
alternative = "two.sided", useTP=TRUE, truncErr=1e-8) |>
as.data.frame() -> locm_ex_typeslocm_ex_types |> hotspot(Prname = "Pr. (exact)",
cutoff = 0.005) -> pol_pres15$locm_exCode
if (tmap4) {
pal <- RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)]
tm_shape(pol_pres15) +
tm_polygons(fill = c("locm_sad2", "locm_ex"),
fill.legend = tm_legend("Turnout hotspot status \nLocal Moran's I",
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01, fill.free = FALSE) +
tm_facets_wrap(rows = 1) +
tm_layout(panel.labels = c("saddlepoint weighted types",
"Exact weighted types"))
} else {
tm_shape(pol_pres15) +
tm_fill(c("locm_sad2", "locm_ex"), colorNA = "grey95",
textNA = "Not \"interesting\"",
title = "Turnout hotspot status \nLocal Moran's I",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(1, 4, 2)]) +
tm_facets(free.scales = FALSE, ncol = 2) +
tm_layout(panel.labels = c("saddlepoint weighted types",
"Exact weighted types"))
}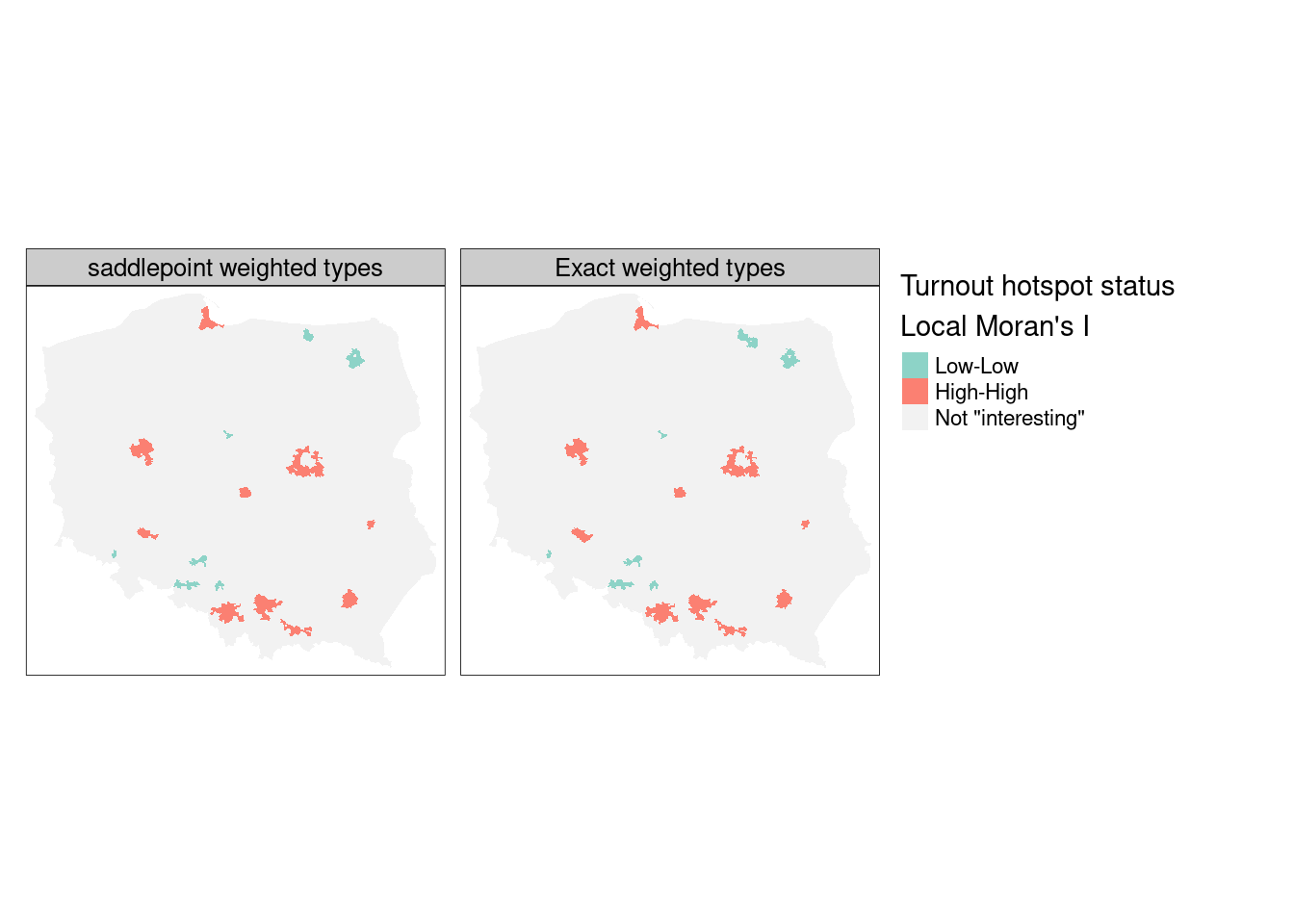
As Figure 15.6 shows, the exact and saddlepoint approximation methods yield almost identical cluster classifications from the same regression residuals, multiple comparison adjustment method, and cutoff level, with the exact method returning four more interesting observations:
Local Getis-Ord \(G_i\)
The local Getis-Ord \(G_i\) measure (Getis and Ord 1992, 1996) is reported as a standard deviate, and, may also take the \(G^*_i\) form where self-neighbours are inserted into the neighbour object using include.self. The observed and expected values of local \(G\) with their analytical variances may also be returned if return_internals=TRUE.
I_turnout |>
localG(lw_q_W, return_internals = TRUE) -> locGPermutation inference is also available for this measure:
I_turnout |>
localG_perm(lw_q_W, nsim = 9999, iseed = 1) -> locG_pThe correlation between the two-sided probability values for analytical and permutation-based standard deviates (first two columns and rows) and permutation rank-based probability values are very strong:
Local Geary’s \(C_i\)
Anselin (2019) extends Anselin (1995) and has been recently added to spdep thanks to contributions by Josiah Parry (pull request https://github.com/r-spatial/spdep/pull/66). The conditional permutation framework used for \(I_i\) and \(G_i\) is also used for \(C_i\):
I_turnout |>
localC_perm(lw_q_W, nsim=9999, iseed=1) -> locC_pThe permutation standard deviate-based and rank-based probability values are not as highly correlated as for \(G_i\), in part reflecting the difference in view of autocorrelation in \(C_i\) as represented by a function of the differences between values rather than the products of values:
Code
if (tmap4) {
pal <- RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)]
m1 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_cp_q",
fill.legend = tm_legend("Turnout hotspot status\nLocal Moran I",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
m2 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_G",
fill.legend = tm_legend("Turnout hotspot status\nLocal Getis/Ord G",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
m3 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_C",
fill.legend = tm_legend("Turnout hotspot status\nLocal Geary C",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = rev(pal), value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
} else {
m1 <- tm_shape(pol_pres15) +
tm_fill("hs_cp_q",
palette = RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title = "Turnout hotspot status\nLocal Moran I") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
m2 <- tm_shape(pol_pres15) +
tm_fill("hs_G",
palette = RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)],
colorNA = "grey95", textNA="Not \"interesting\"",
title = "Turnout hotspot status\nLocal Getis/Ord G") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
m3 <- tm_shape(pol_pres15) +
tm_fill("hs_C",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1, 3)],
colorNA = "grey95", textNA="Not \"interesting\"",
title = "Turnout hotspot status\nLocal Geary C") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
}
tmap_arrange(m1, m2, m3, nrow=1)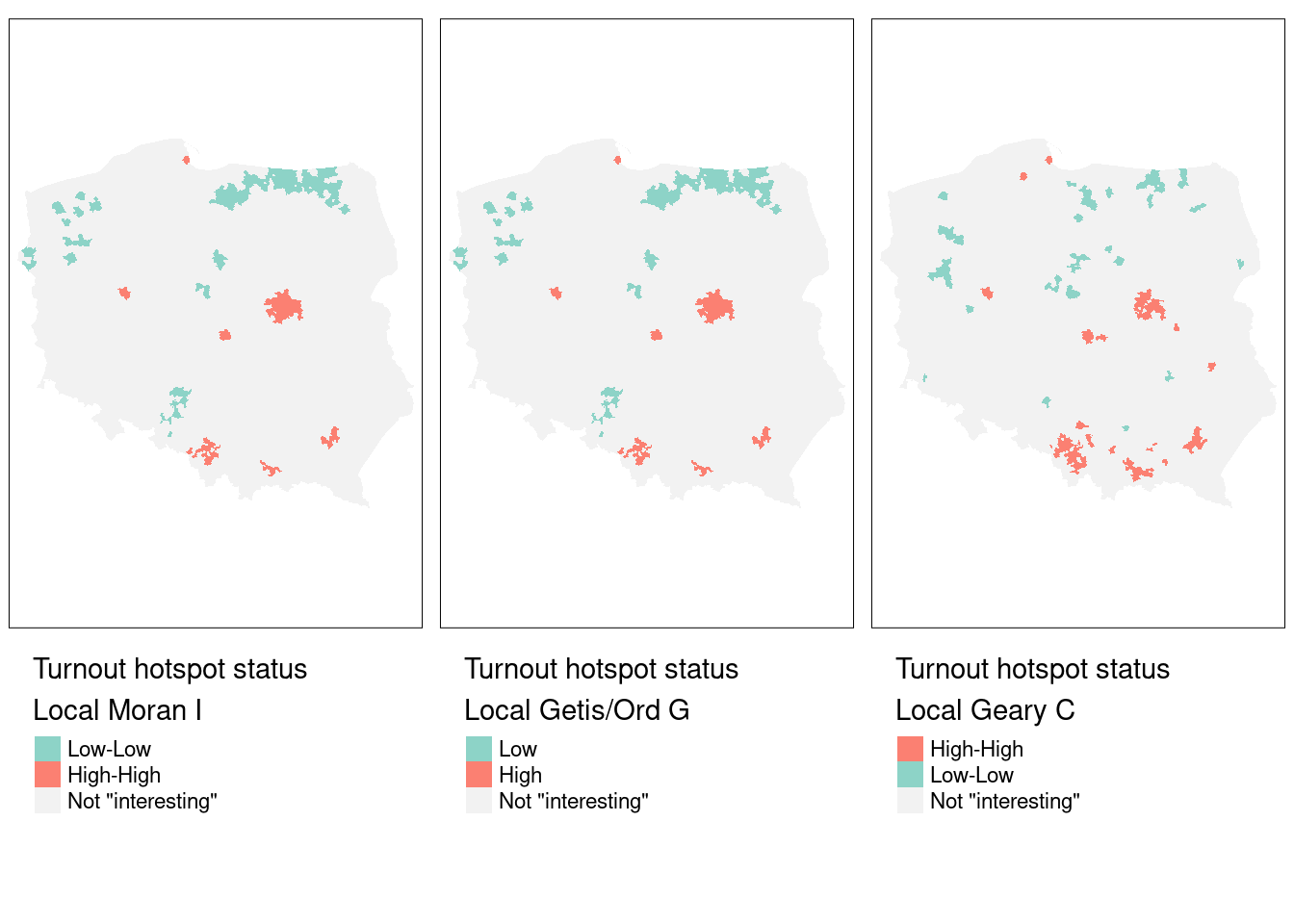
Figure 15.7 shows that the cluster cores identified as interesting using \(I_i\), \(G_i\) and \(C_i\) for the same variable, first-round turnout, and the same spatial weights, for rank-based permutation FDR adjusted probability values and an \(\alpha = 0.005\) cutoff, are very similar. In most cases, the "High-High" cluster cores are urban areas, and "Low-Low" cores are sparsely populated rural areas in the North, in addition to the German national minority areas close to the southern border. The three measures use slightly different strategies for naming cluster cores: \(I_i\) uses quadrants of the Moran scatterplot, \(G_i\) splits into "Low" and "High" on the mean of the input variable (which is the same as the first component in the \(I_i\) tuple), and univariate \(C_i\) on the mean of the input variable and zero for its lag. As before, cluster categories that do not occur are dropped.
For comparison, and before moving to multivariate \(C_i\), let us take the univariate \(C_i\) for the second (final) round turnout. One would expect that the run-off between the two top candidates from the first-round might mobilise some voters who did not have a clear first-round preference, but that it discourages some of those with strong loyalty to a candidate eliminated after the first round:
pol_pres15 |>
st_drop_geometry() |>
subset(select = II_turnout) |>
localC_perm(lw_q_W, nsim=9999, iseed=1) -> locC_p_IIlocC_p_II |> hotspot(Prname = "Pr(z != E(Ci)) Sim",
cutoff = 0.005) -> pol_pres15$hs_C_IIMultivariate \(C_i\) (Anselin 2019) is taken as the sum of univariate \(C_i\) divided by the number of variables, but permutation is fixed so that the correlation between the variables is unchanged:
pol_pres15 |>
st_drop_geometry() |>
subset(select = c(I_turnout, II_turnout)) |>
localC_perm(lw_q_W, nsim=9999, iseed=1) -> locMvC_pLet us check that the multivariate \(C_i\) is equal to the mean of the univariate \(C_i\):
all.equal(locMvC_p, (locC_p+locC_p_II)/2,
check.attributes = FALSE)
# [1] TRUElocMvC_p |> hotspot(Prname = "Pr(z != E(Ci)) Sim",
cutoff = 0.005) -> pol_pres15$hs_MvCCode
if (tmap4) {
pal <- RColorBrewer::brewer.pal(4, "Set3")[-c(2,3)]
m3 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_C",
fill.legend = tm_legend("First round turnout\nLocal Geary C",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = rev(pal), value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
pal <- RColorBrewer::brewer.pal(4, "Set3")[c(4, 1, 3, 2)]
m4 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_C_II",
fill.legend = tm_legend("Second round turnout\nLocal Geary C",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
pal <- RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)]
m5 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_MvC",
fill.legend = tm_legend("Both rounds turnout\nLocal Multivariate Geary C",
position = tm_pos_out("center","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale_categorical(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01) +
tm_layout(meta.margins = c(.2, 0, 0, 0))
} else {
m3 <- tm_shape(pol_pres15) +
tm_fill("hs_C",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1, 3, 2)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title = "First round turnout\nLocal Geary C") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
m4 <- tm_shape(pol_pres15) +
tm_fill("hs_C_II",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1, 3, 2)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title="Second round turnout\nLocal Geary C") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
m5 <- tm_shape(pol_pres15) +
tm_fill("hs_MvC",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title = "Both rounds turnout\nLocal Multivariate Geary C") +
tm_layout(legend.outside=TRUE, legend.outside.position="bottom")
}
tmap_arrange(m3, m4, m5, nrow=1)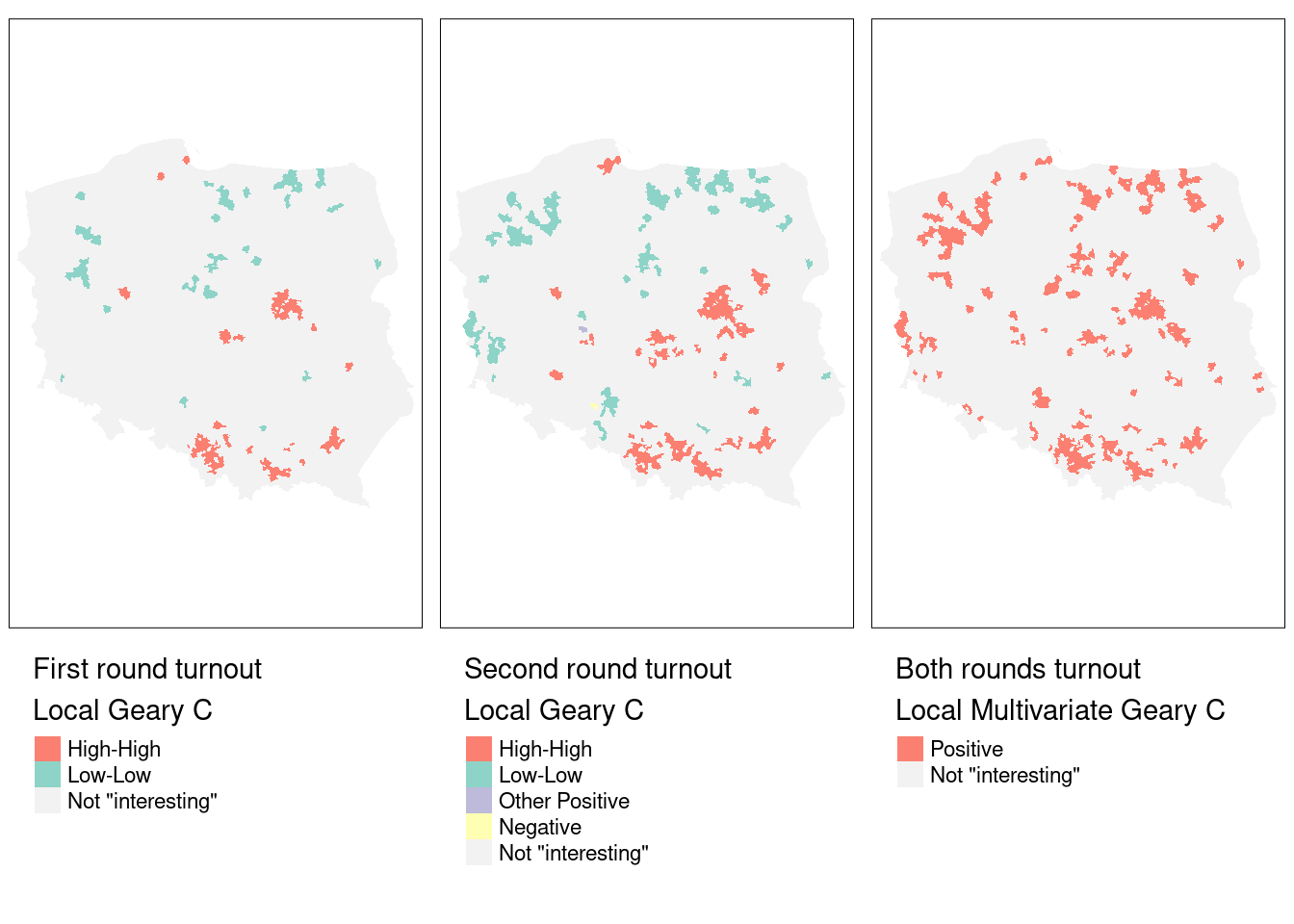
Figure 15.8 indicates that the multivariate measure picks up aggregated elements of observations found interesting in the two univariate measures. We can break this down by interacting the first- and second-round univariate measures, and tabulating against the multivariate measure.
table(droplevels(interaction(addNA(pol_pres15$hs_C),
addNA(pol_pres15$hs_C_II), sep=":")),
addNA(pol_pres15$hs_MvC))
#
# Positive <NA>
# High-High:High-High 81 0
# NA:High-High 41 27
# Low-Low:Low-Low 25 0
# NA:Low-Low 43 11
# NA:Other Positive 1 0
# NA:Negative 0 1
# High-High:NA 15 0
# Low-Low:NA 11 3
# NA:NA 36 2200For these permutation outcomes, 47 observations in the multivariate case are found interesting where neither of the univariate \(C_i\) were found interesting (FDR, cutoff \(0.005\)). Almost all of the observations found interesting in both first and second round, are also interesting in the multivariate case, but outcomes are more mixed when observations were only found interesting in one of the two rounds.
The rgeoda package
Geoda has been wrapped for R as rgeoda (Li and Anselin 2022), and provides very similar functionalities for the exploration of spatial autocorrelation in areal data as matching parts of spdep. The active objects are kept as pointers to a compiled code workspace; using compiled code for all operations (as in Geoda itself) makes rgeoda perform fast, but makes it less flexible when modifications or enhancements are desired.
library(rgeoda)
Geoda_w <- queen_weights(pol_pres15)
summary(Geoda_w)
# name value
# 1 number of observations: 2495
# 2 is symmetric: TRUE
# 3 sparsity: 0.00228786229774178
# 4 # min neighbors: 1
# 5 # max neighbors: 13
# 6 # mean neighbors: 5.70821643286573
# 7 # median neighbors: 6
# 8 has isolates: FALSEFor comparison, let us take the multivariate \(C_i\) measure of turnout in the two rounds of the 2015 Polish presidential election as above:
lisa <- local_multigeary(Geoda_w,
pol_pres15[c("I_turnout", "II_turnout")],
cpu_threads = max(detectCores() - 1, 1),
permutations = 99999, seed = 1)The contiguity neighbours are the same as those found by poly2nb:
all.equal(card(nb_q), lisa_num_nbrs(lisa),
check.attributes = FALSE)
# [1] TRUEas are the multivariate \(C_i\) values the same as those found above:
all.equal(lisa_values(lisa), c(locMvC_p),
check.attributes = FALSE)
# [1] TRUEOne difference is that the range of the folded two-sided rank-based permutation probability values used by rgeoda is \([0, 0.5]\), also reported in spdep:
This means that the cutoff corresponding to \(0.005\) over \([0, 1]\) is \(0.0025\) over \([0, 0.5]\):
locMvC_p |> hotspot(Prname = "Pr(folded) Sim",
cutoff = 0.0025) -> pol_pres15$hs_MvCaSo although local_multigeary used the default cutoff of \(0.05\) in setting cluster core classes, we can sharpen the cutoff and apply the FDR adjustment on output components of the lisa object in the compiled code workspace:
mvc <- factor(lisa_clusters(lisa), levels=0:2,
labels = lisa_labels(lisa)[1:3])
is.na(mvc) <- p.adjust(lisa_pvalues(lisa), "fdr") >= 0.0025
pol_pres15$geoda_mvc <- droplevels(mvc)About 80 more observations are found interesting in the rgeoda permutation, and further analysis of implementation details is still in progress:
addmargins(table(spdep = addNA(pol_pres15$hs_MvCa),
rgeoda = addNA(pol_pres15$geoda_mvc)))
# rgeoda
# spdep Positive <NA> Sum
# Positive 249 4 253
# <NA> 75 2167 2242
# Sum 324 2171 2495Code
if (tmap4) {
pal <- RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)]
m5 <- tm_shape(pol_pres15) +
tm_polygons(fill = "hs_MvC",
fill.legend = tm_legend("Both rounds turnout spdep\nLocal Multivariate Geary C",
position = tm_pos_in("left","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale_categorical(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01)
m6 <- tm_shape(pol_pres15) +
tm_polygons(fill = "geoda_mvc",
fill.legend = tm_legend("Both rounds turnout rgeoda\nLocal Multivariate Geary C",
position = tm_pos_in("left","bottom"),
frame = FALSE, item.r = 0),
fill.scale = tm_scale_categorical(values = pal, value.na = "grey95",
label.na = "Not \"interesting\""),
lwd = 0.01)
} else {
m5 <- tm_shape(pol_pres15) +
tm_fill("hs_MvCa",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title = "Both rounds turnout spdep\nLocal Multivariate Geary C")
m6 <- tm_shape(pol_pres15) +
tm_fill("geoda_mvc",
palette = RColorBrewer::brewer.pal(4, "Set3")[c(4, 1)],
colorNA = "grey95", textNA = "Not \"interesting\"",
title="Both rounds turnout rgeoda\nLocal Multivariate Geary C")
}
tmap_arrange(m5, m6, nrow=1)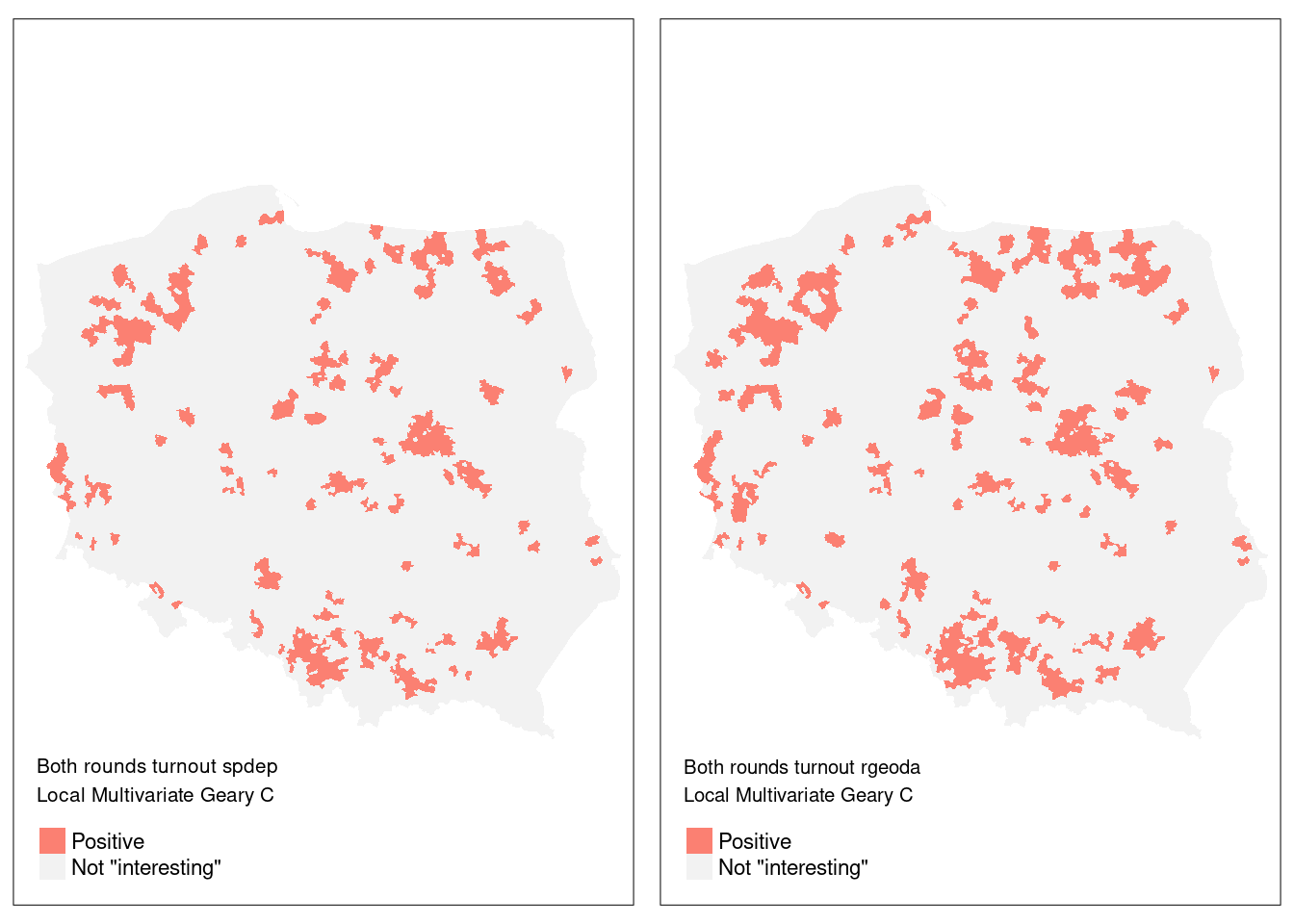
Figure 15.9 shows that while almost all of the 242 observations found interesting in the spdep implementation were also interesting for rgeoda, the latter found a further 86 interesting. Of course, permutation outcomes are bound to vary, but it remains to establish whether either or both implementations require revision.
15.4 Exercises
- Why are join-count measures on a chessboard so different between
rookandqueenneighbours? - Please repeat the simulation shown in Section 15.1 using the chessboard polygons and the row-standardised
queencontiguity neighbours. Why is it important to understand that spatial autocorrelation usually signals (unavoidable) misspecification in our data? - Why is false discovery rate adjustment recommended for local measures of spatial autocorrelation?
- Compare the local Moran’s \(I_i\) standard deviate values for the simulated data from exercise 2 (above) for the analytical conditional approach, and saddlepoint approximation. Consider the advantages and disadvantages of the saddlepoint approximation approach.